A primer to model queries
Models are not black holes
The principle of model-driven engineering (MDE) was discussed in my previous blog post. When one reads about MDE, there is a lot of talk about creating models, as if all the engineers ever do was creating models using shiny diagram editors; like "the focus of the engineering approach is to build models of the system under design, first on a high level of abstraction, then gradually approaching platform-specific design decisions", and so on. One could even start to believe that models are some kind of information theory black hole: information is only put in, but never comes out. Well, this is not the case.
The purpose of models is not just to archive knowledge and ideas, but to contain, structure, organize, preserve and communicate them, to make them available for use in the engineering workflow. The information within models is put there exactly because it will be used later. Processing models is as much a key part of MDE as the act of creating models. In fact, the aforementioned shiny diagram editors typically also rely on extraction of information from models somewhere under the hood. A good example of this would be such an editor offering options to fill in some data somewhere; for instance the choices available for the type of a field in a class model of an object-oriented system are gathered by processing the same class model.
Why else do we need to process models?
Apart from basic editing support, model processing is relevant in a number of scenarios. Most importantly, it is vital in supporting the analysis of models. The most straightforward kind of analysis is static analysis, which may range from simple cases such as finding missing elements (e.g. unspecified carrier bus for a signal in embedded system design) to more complex cases such as detecting subtle contradictions (e.g. scheduling conflict among signals of the same bus).
There is also dynamic analysis, which emulates a behavioural model to examine its trajectories (possible course of events). Use cases include testing, performance and reliability simulation, and model checking of safety-critical systems. A discrete-time dynamic analysis will, at each visited state of the system, determine potential evolution by processing the model and identifying state transitions that are currently enabled.
In case of MDE, one should not forget that models are very often derived from other existing models. Model transformation is the automation of these steps, the task of processing a model to create, extend or change models based on the information contained within it. As a special case, code generation or model-to-text (M2T) transformation applies the concept to synthesizing textual targets, typically program code.
What are model queries?
In all of the cases discussed above, the processing of models is performed by the modeling / model analysis / model transformation tools . These are software programs that were developed in an arbitrary programming language to form a modeling environment specific to the modeling domain and engineering workflows; see the previous discussion on domain-specific modeling. Complex model processing, however, requires error-prone and labour-intensive tool development for each DSML, and the resulting tooling might not conform to performance best practices.
The solution to this family of problems is well-known in the software industry, particularly in the field of databases. Instead of implementing the entire task of model processing in a general-purpose programming language, industry prefers the separation of the declarative query specification (concisely and intuitively expressing the model processing intent of the tool developer) from the query evaluator engine (specialized for efficiently processing models of a DSM technology such as EMF to obtain the correct query results).
How does one issue model queries?
Queries can be issued by writing a query specification in a dedicated query language, and passing it to an evaluator engine along with the instance model to be processed.
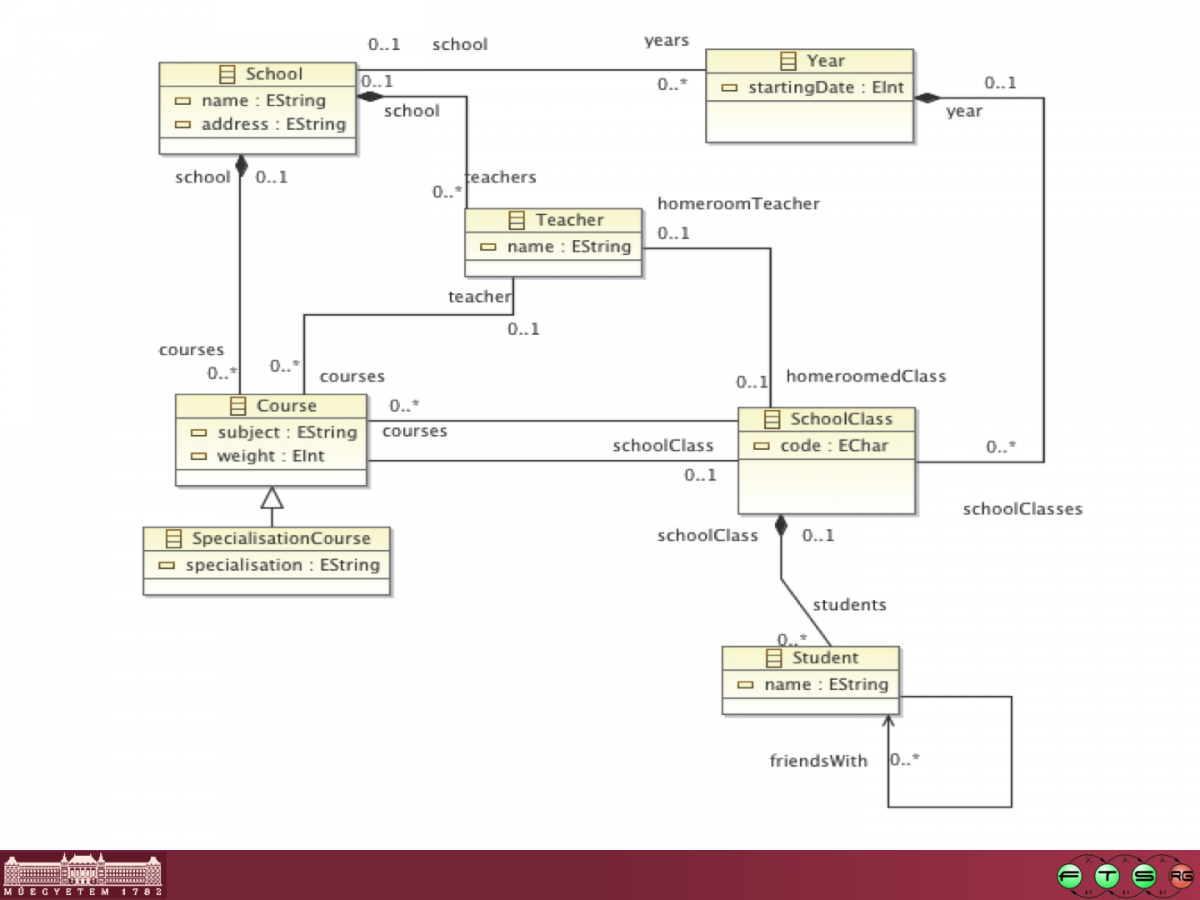
For instance, in the toy example EMF-based DSM language of this tutorial page, one can record the students, classes and teachers of schools. Let's say we want to know whether there are multiple students with the same name in the same class; we would presumably want to reassign some of these students to parallel classes in order to simplify bookkeeping. If the query engine was a human being capable of understanding plain English, a query could be "for this particular SchoolClass, find all pairs of Students among the students of the SchoolClass, for which the two Students share their name". Now we only need a formal language for the precise specification of this query, and a query engine that understands this language.
Below, we will briefly discuss how one can deal with this problem in two industrial model query languages.
OCL
The Object Constraint Language[OMG Spec], abbrev. OCL, is a well-known query formalism for MOF, EMF and many other modeling technologies. The following code is an OCL formalization of the above query:
context SchoolClass def:
nameConflicts(): Set(TupleType(student1: Student, student2:Student, name:EString)) =
self.students->collect(s1 | self.students->select(s2 | s2.name = s1.name and s1 <> s2)->
collect(s2 | Tuple{student1 = s1, student2 = s2, name = s1.name}))For each ScoolClass, this OCL code defines an unparameterized named expression "nameConflicts" that will return a set of tuples formed by two students and a character string. The result is obtained this way: for the SchoolClass (which will hencefort be known as "self"), we take the list of students; then for each student "s1" on this list, we collect the tuples of name conflicts involving that specific student. How do we do the latter? Again from all students of the SchoolClass "self", we first select a limited set consisting only of those Students "s2" that have the same name as "s1" and are different from "s1" ("<>" means "not the same as"). Then for each Student "s2" to be found in this limited selection, we collect a tuple composed of "s1", "s2" and the name of "s1".
An in-depth introduction of OCL is not given here; the standardized specification document contains a formal definition as well as an informal introduction of the language.
Graph patterns and EMF-IncQuery
Graph patterns are a highly declarative way of intuitively specifying certain kinds of model queries. In case of the EMF platform, EMF-IncQuery[homepage] is a query technology featuring a query language based on graph patterns. The following code is an EMF-IncQuery formalization of the above query:
pattern nameConflicts(clazz: SchoolClass, student1: Student, student2: Student, name: EString) = {
SchoolClass.students(clazz, student1);
SchoolClass.students(clazz, student2);
student1 != student2;
Student.name(student1, name);
Student.name(student2, name);
}
The above code introduces a graph pattern with the four parameter variables "clazz" of type SchoolClass, "student1" and "student2" of type Student, and "name" of type EString. By the semantics of the language, the pattern has a set of matches that are tuples formed of four elements, each taken from the model and offered as substitution for one of the four parameter variables. The match set will contain exactly those tuples whose variable substitutions satisfy the pattern constraints. In this case, the constraints are that (a) both "student1" and "student2" are reachable from "clazz" via a SchoolClass,students edge, (b) "student1" and "student2" are different, as denoted here by the "!=" operator, and (c) both Students have the value of variable "name" as their name.
The actual query would be this graph pattern, with the parameter variable "clazz" bound to a given input SchoolClass. In this case, the pattern matcher will only return those matches that belong to the given value of "clazz".