EMF-IncQuery Documentation
Getting Started
The content of this page is deprecated, use the following sites instead:
- https://www.eclipse.org/incquery/download.php
- http://wiki.eclipse.org/EMFIncQuery/UserDocumentation/Installation
Installation
Prerequisites:
JDK 6 (JDK7 will also work)Eclipse Modeling 3.7.2 or newer (we regularly test and develop with Eclipse 4.2 Juno)Xtext SDK 2.3, Xtend SDK 2.3available from http://download.eclipse.org/modeling/tmf/xtext/updates/composite/releases/it is best to start with the Juno Modeling Tools distribution and then install Xtext and Xtend from the Eclipse MarketplaceWarning! There are known issues with the upcoming Xtext/Xtend 2.4 release. As of now, you cannot use EMF-IncQuery with this version.
Some tips for the installation:
Uncheck "Contact all update sites during install to find required software" to ensure reasonable performance during the installation processIf you have some other Eclipse Indigo installation, make sure to uninstall older versions of Xtext, Xtend and MWE2 before installing Xtext and Xtend 2.3Only check Xtext SDK and Xtend SDK features, the rest will be added automaticallyIt is best to use a fresh, new workspace for experimentation
Update site for EMF-IncQuery:
EMF-IncQuery is available from eclipse.org - see http://eclipse.org/incquery/download.php
Creating your first query
The built-in cheat sheet should help you with the first steps. We also maintain a web-based tutorial here. Additionally, you can check the School and BPMN introductory walkthrough examples to help you get started.
Examples
You can find a list of more complex examples here.
Next steps
A few pointers to move on from here:
IncQuery FAQGuide for performance benchmarkingDevelopers' Guide (if you wish to contribute to IncQuery)Testers' Guide
Technology Overview
"New Generation" (versions 0.6.x and beyond) represent an almost complete rewrite of IncQuery technology.
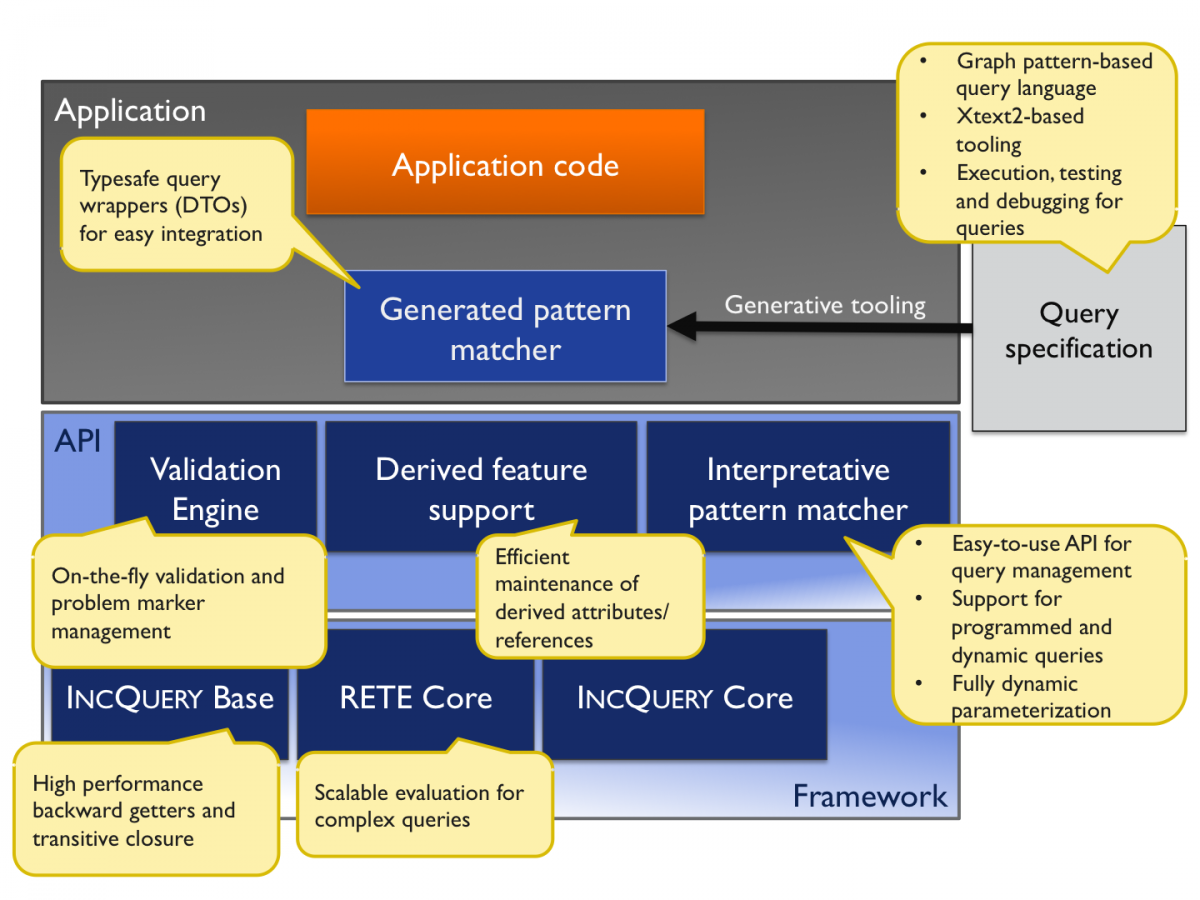
IncQuery supports the following new features (with respect to 0.4):
- an interpretative query API, enabling query developers to invoke model queries without having to generate code (to speed up development)
- a new, Xtext2-based development environment, with full support for any EMF domain
- full support for incremental transitive closures and core backward getters through IncQuery Base
- integrated support for add-ons such as derived features, standalone mode and the Validation Engine
Runtime and API
The complex query evaluator of the EMF-IncQuery framework is built on a graph pattern matching engine that uses the Rete algorithm, adapted from expert systems to facilitate the efficient storage and retrieval of partial views of graph-like models. EMF-IncQuery also features the Base component that provides incremental support for backward getters as well as transitive closures for the efficient computation of e.g. reachability regions. EMF-IncQuery relies on the EMF Notification facility to incrementally update its internal cache to guarantee the consistency of the result set with respect to the actual contents of the model.
As an interface over the core algorithms, the new IncQuery runtime consists of:
- a query / pattern matching API that provides a typesafe wrapper for instantiating and executing queries over EMF Notifiers (Resources, ResourceSets and EObject hierarchies)
- add-ons such as the Validation Framework (for the specification and on-the-fly execution of well-formedness rules, corresponding to Eclipse Resource Markers) or Derived feature support (for the efficient evaluation of derived EAttributes and EReferences with IncQuery queries as back-ends, that can be used for soft interlinks)
The runtime is designed to be compatible with standard Eclipse-EMF configurations as well as a headless, standalone execution mode. The efficiency of the execution engine has been demonstrated in an industrial setting as well as in several academic research case studies.
Tooling and language
The new IncQuery tooling consists of an Xtext-based pattern language editor, and a development UI that can be used to execute, test and debug queries within the Eclipse IDE. The tooling can make use of the interpretative runtime API for on-the-fly query execution and testing, while it can also generate type-safe wrappers that ease the integration of queries into application code. The tooling also interfaces with IncQuery’s add-ons to generate feature-specific adapter code.
IncQuery’s declarative queries can be evaluated over EMF models without manual (programmed) traversal. The query language is built upon the concepts of graph patterns (which is a key concept in many transformation tools) to provide a concise, reusable and easy way to specify complex structural model queries. The key features are:
- complex interconnections of EMF objects can be easily formulated as a graph pattern,
- the language is highly expressive and provides powerful features such as negation or counting,
- queries can be evaluated with great freedom, i.e. input and output parameters can be bound freely at evaluation time,
- graph patterns are composable, making it possible to build reusable query libraries.
Defining Model Queries using EMF-IncQuery
Outdated content
The contents of this page have been superseded by the following page on the Eclipse Wiki:
http://wiki.eclipse.org/EMFIncQuery/UserDocumentation/QueryDevelopment
Overview
EMF-IncQuery provides an intuitive user interface to create, edit and debug queries. It assists users with various wizards, supports the editing of query definitions (patterns) in an Xtext-based editor and also provides query debugging features with the Query Explorer view.
The main components:
- Wizards: there are wizards available to create EMF-IncQuery project, generator model and queries. These wizards are available under the EMF-IncQuery category when creating new resources (see the picture below)
- Query editor: the Xtext-based editor can be used to create EMF-IncQuery queries. The editor provides many features to ease the development, such as automatic code completion, validation, etc.
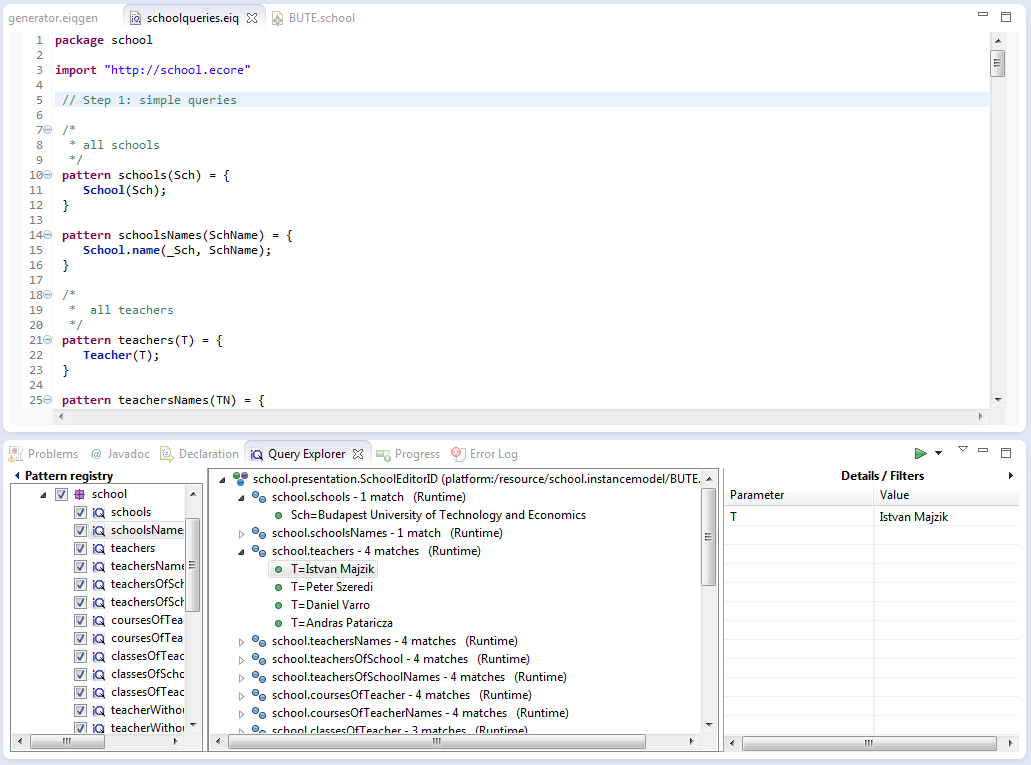
- Query Explorer: this view can be used to apply queries on various EMF instance models. The Query Explorer can interact with EMF-based editors such as the generated tree editor, and even with GMF and Graphiti editors. Advanced querying use cases, like pattern match set filtering and detail observation is also available with the Query Explorer. The following picture presents the Pattern Editor and the Query Explorer view.
Use cases
New EMF-IncQuery project
EMF-IncQuery project is the container of all EMF-IncQuery related artifacts. The wizard can be found under the EMF-IncQuery category.
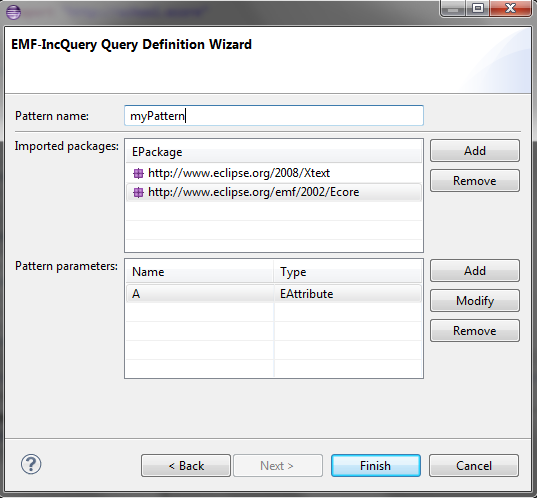
New EMF-IncQuery query definition
The wizard first guides you through the creation of the query container (package) which is similar to the creation of a Java class. The second page helps you create an initial pattern within your new .eiq file. Here you can name your pattern, select the packages that you want to use in your patterns and add pattern parameters with type specification. After finishing with the wizard a new .eiq file will be created with the pattern specified on the second page.
New EMF-IncQuery generator model
If you wish to work with an EMF domain that is present as a source project in your workspace, you have to create an EMF-IncQuery generator model that will contain a reference to the .genmodel file of your EMF domain. Inside the file you must specify the resource URI of the genmodel file.
Editing queries
It is best to start with the built-in pattern template (available as a code completion feature). The details of the EMF-IncQuery Query Language are discussed on the language documentation page. The School example might also provide useful starting points.
Executing and debugging queries
The Query Explorer View can be used to execute and debug the queries on EMF instance models. The main features of the Query Explorer view are:
- You can load your queries into the Query Explorer by pressing the green button on the top right corner of the view. In order to apply queries to a concrete instance model, the queries have to be loaded.
- EMF instance models can be loaded from EMF-based editors such as the generated or reflective EMF tree editors, GMF and Graphiti editors. There are two alternatives when loading such models:
- You can load the whole ResourceSet which is being edited by the editor (this is the default when pressing the green button)
- You can load the Resource of the selected element within the editor which can be done with the appropriate element from the view menu of the green button.
- If at least one query and instance model is loaded, the middle section of the Query Explorer will present the match sets in a tree structure. The top level element corresponds to an editor-instance model pair (because the same instance model can be loaded from different editors and the reversed way is also possible). The elements under the top level elements correspond to the queries and the low-level elements represent the match set of the given query. Note that the contents of the tree viewer are automatically updated upon changes occurring in the match sets of the pattern.
- The Pattern Registry on the left shows the loaded patterns according to the package hierarchy. It distinguishes them by their source, either coming from a generated EMF-IncQuery project from the host workspace or manually loaded ones from the runtime Eclipse. You can select and deselect single patterns or groups of patterns inside the Pattern Registry which will result the loading and unloading of queries for every instance model loaded into the Query Explorer. You can also change the way of package presentation (flat or hierarchical) in the view menu of the Query Explorer.
- Details and filter section on the right side of the view: the view of this content is based on the selection inside the tree viewer. If you select a pattern then you can specify filters on the pattern parameters (this use case is discussed later in this document). However, if you select a single match, you can observe the values of the pattern parameters which are data bound to the appropriate model elements thus automatically refreshed upon match changing. The latter use case can be influenced with the @ObservableValue annotation, which is described in depth on the Databinding documentation page.
- Almost all elements in the view provides Show Location (in the context menu) functionality which connects the element with its source. For example, if you click the Show Location on a match of a pattern, the appropriate elements will be selected in the editor which is associated to the EMF instance model. Additionally, if you click Show location on a pattern inside the Pattern Registry it will show you the pattern definition in your .eiq file.
- Patterns and instance models can be unloaded from the Query Explorer by clicking Unload model in the context menu. Additionally, if you close the editor of an instance model that is loaded into the Query Explorer, it will automatically unload it.
- Note that, modifying the contents of a .eiq file - that was loaded earlier to the Query Explorer - automatically triggers re-loading of the patterns.
Advanced use cases
Pattern Annotations supported by the Query Explorer
The IncQuery Language allows to use annotations for pattern definitions to fine-tune the behavior of a query. The following annotations are supported by the Query Explorer:
- @ObservableValue: Defines observable values for the pattern's parameters. Although it is basically used to generate accessors for such values to use in databinding contexts, the Query Explorer also presents these values. See the databinding page for detailed usage.
- @PatternUI (deprecated): Defines the label that will be used in the Query Explorer for the pattern's matches. This annotation is deprecated, please use the @QueryExplorer instead.
- @QueryExplorer: The annotation can be used to define the way to present the pattern and its match set in the Query Explorer. The annotations defines the following parameters
- display (Boolean): sets whether the pattern should be displayed in the Query Explorer automatically.
- message (String): the message to be displayed for a specific match, for example "The busiest teacher $T.name$ taught the most sociable student $S.name$ in $Y.startingDate$"- from the school example. Between the '$' marks one can refer to attributes of pattern parameters that will be substituted with the concrete values during runtime.
- @OrderBy: Annotate a pattern with OrderBy to define ordering between matches displayed in the Query Explorer.
See the hover help (provided by the query editor) for more details on annotations.
Parameterized queries
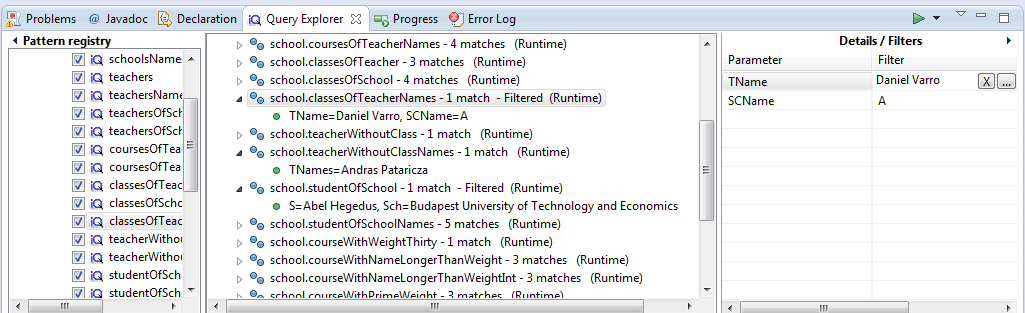
In the Query Explorer you can define filters for the registered patterns. This specification is, however, instance model and pattern-specific (does not apply for the same pattern under different instance model). The aim of this facility is to narrow down the match sets of specific patterns when debugging. The following steps are required to specify a filter:
- Load an instance model and some queries into the Query Explorer.
- Select a pattern in the tree viewer. The details/filters view will be initialized for filtering.
- You can set filters for each one of the pattern parameters by clicking on the button on the right side of the text input.
- The content of the input field cannot be modified by hand for complex types - they can be selected from the popup window and only model elements from the given instance model is allowed to select. For primitive types, the value can be input directly and it is validated according to the type of the parameter.
See the following picture for an example filtering from the school example.
Wildcard mode
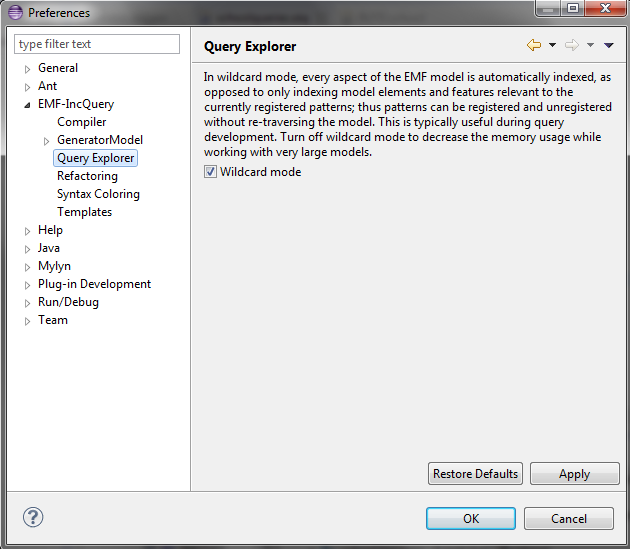
Settable on the EMF-IncQuery preference settings page: in wildcard mode, every aspect of the EMF model is automatically indexed, as opposed to only indexing model elements and features relevant to the currently registered patterns; thus patterns can be registered and unregistered without re-traversing the model. This is typically useful during query development. Turn off wildcard mode to decrease the memory usage while working with very large models.
Query Language
Overview
Language concepts
For the query language, we reuse the concepts of graph patterns (which is a key concept in many graph transformation tools) as a concise and easy way to specify complex structural model queries. These graph-based queries can capture interrelated constellations of EMF objects, with the following benefits:
- the language is expressive and provides powerful features such as negation or counting,
- graph patterns are composable and reusable,
- queries can be evaluated with great freedom, i.e. input and output parameters can be selected at run-time,
-
some frequently encountered shortcomings of EMF’s interfaces are addressed:
- easy and efficient enumeration of all instances of a class regardless of location,
- simple backwards navigation along all kinds of references (even without eOpposite)
- finding objects based on attribute value.
Basic documentation
The current version of the IncQuery Graph Pattern language (IQPL) owes many of its syntax to the VTCL language of model transformation framework VIATRA2. If you would like to read more on the foundations of the new language, we kindly point you to our ICMT 2011 paper (important note: the most up-to-date IncQuery language syntax differs slightly from the examples of the ICMT paper).
Short syntax guide
See also the language tutorial and the School example.
-
Import declarations are required to indicate which EMF packages are referenced in the query definitions.
-
Use the registered namespace URI for import declarations. Content assist is available:
import "http://my.own.ePackage.nsUri/1.0"
-
Use the registered namespace URI for import declarations. Content assist is available:
-
Enclose pattern definitions in a package:
package my.own.patterns -
Introduce a pattern by the pattern keyword, a pattern name, and a list of parameter variables. Then enclose in curly braces a list of constraints that define when the pattern should match.
pattern myPattern(A,B,C) = {...pattern contraints...} -
Disjunction ("or") can be expressed by linking several pattern bodies with the or keyword:
pattern myPattern(A,B,C) = {... pattern contraints ...} or {... pattern constraints ...} -
The most basic pattern constraints are type declarations: use EClasses, ERelations and EAttributes. The data types should also be fine.
-
An EClass constraint expressing that the variable MyEntityVariable must take a value that is an EObject of the class MyClass (from EPackage my.own.ePackage, as imported above) looks like this:
MyClass(MyEntityVariable); -
A relation constraint for the EReference MyReference expressing that MyEntityVariable is of eClass MyClass and its MyReference EReference is pointing to TheReferencedEntity (or if MyReference is many-valued, then it is one of the target object contained in the EList), as seen below:
MyClass.MyReference(MyEntityVariable, TheReferencedEntity); -
A relation constraint for an EAttribute, asserting that TheAttributeVariable is the String/Integer/etc. object that is the MyAttribute value of MyEntityVariable, looks exactly the same as the EReference constraint:
MyClass.MyAttribute(MyEntityVariable, TheAttributeVariable); -
Such reference navigations can be chained; the last step may either be a reference or attribute traversal:
MyClass.MyReference.ReferenceFromThere.AnotherReference.MyAttribute(MyEntityVariable, MyString); -
Pattern parameters can be suffixed by a type declaration, that will be valid in each pattern body. Here is an alternative way to express the type of variable B:
pattern myPattern(A,B : MyClass,C) = {...pattern contraints...}; -
(You will probably not need this, but EDatatype type constraints can be applied on attribute values, with a syntax similar to that used for EObjects, and with the additional semantics that the attribute value must come from the model, not just any int/String/etc. computed e.g. by counting):
MyDatatype(MyAttributeVariable);
or for the built-in datatypes (import the Ecore metamodel):
EString(MyAttributeVariable);
-
An EClass constraint expressing that the variable MyEntityVariable must take a value that is an EObject of the class MyClass (from EPackage my.own.ePackage, as imported above) looks like this:
-
By default, each variable you define may be equal to each other variable in a query. This is especially important to know when using attributes or multiple variables with the same type (or supertype).
- For example, if you have two variables MyClass(SomeObj1), MyClass(SomeObj2), SomeObj1 and SomeObj2 may match to the same EObject.
-
If you want to declare that two variables mustn't be equal, you can write:
SomeObj1 != SomeObj2; -
If you want to declare, that two variables must be the same, you can write:
SomeObj1 == SomeObj2;
-
Pattern composition: you can reuse a previously define pattern by caling it in a different pattern's body:
find otherPattern(OneParameter, OtherParameter, ThirdParameter); -
You can express negation with the neg keyword. Those actual parameters of the negative pattern call that are not used elsewhere in the calling body will be quantified; this means that the calling pattern only matches if no substitution of these calling variables could be found. See examples in order to understand. The below constraint asserts that for the given value of the (elsewhere defined) variable MyEntityVariable, the pattern neighborPattern does not match for any values of OtherParameter (not mentioned elsewhere).
neg find neighborPattern(MyEntityVariable, OtherParameter); -
In the above constraints, wherever you could use an (attribute) variable in a pattern body, you can also use:
-
Constant literals of primitive types, such as
10, or"Hello World". -
Constant literals of enumeration types, such as
MyEEnum::MY_LITERAL -
Aggregation of multiple matches of a called pattern into a single value. Currently match counting is supported, in a syntax analogous to negative pattern calls:
HowManyNeighbors == count find neighborPattern(MyEntityVariable, OtherParameter); - Attribute expression evaluation: coming soon.
-
Constant literals of primitive types, such as
-
Additional attribute constraints using the check() construct:
check((A as Integer) > (S as String).length()); -
One can also use the transitive closure of binary patterns in a pattern call, such as the transitive closure of pattern friend:
find friend+(MyGuy, FriendOfAFriendOfAFriend);
Limitations (as of IncQuery 0.6)
- Meta-level queries (instanceOf etc.) will not currently work (although Ecore models can be processed as any other model).
-
Make sure that the result of the check() expressions can change ONLY IF one of the variables defined in the query changes.
- In practice, a good rule of thumb is to only use attribute variables or other scalar values in a check(), no EObjects.
-
In particular, do not call non-constant methods of EObjects in a check(). Use attribute values instead, if necessary converted to the native type using (SomeInt as Integer) and co, so as to help the type inference.
- For example, you CAN use check((Name as String).contains(SomeString as String)).
- But You MUSTN'T use check((SomeObject as MyClass).name.contains((SomeString as String)) as the name of SomeObject can change without SomeObject changing!
- Use only well-behaving derived references or attributes. Better yet, reimplement the derived feature using queries. Regular derived features are not supported in patterns (except the ones in the Ecore metamodel, which are well-behaving by default) as they can have arbitrary Java implementations and EMF-IncQuery is unable to predict when their value will change.
See advanced issues for additional topics, such as attribute handling.
Step-by-step tutorial
Note: the built-in cheat sheet of EMF-IncQuery should also provide help in getting started.
Creating your first query
- src (for manually written code)
- src-gen (for generated code)
Using other structural constraints
Note, that currently this will cause type inference for the generated Match class to fail, so the parameters Cls and Name will be returned as Objects.
Check expressions and constants
It is possible to add constraints for the values of attribute variables in a query, these are called check expressions in EMF-IncQuery. For example, if you would like to ensure, that the name of the selected EClass is "MyClass", it can be done as follows:
Similarly, you can use other methods inside a check, for example compare numbers (after similar casting) or even use methods of the attribute values, such as String.contains(). Note, that you should only use methods which (1) have deterministic results, so they return the same value for the same EObject and (2) their results only change when the EObject itself changes, otherwise incremental updates will not work correctly.
If you only need equality checks for attribute values, you can simply replace the variable with the constant value, e.g.:
Injectivity constraints
By default, if you have two variables in the same query with the same type, then these variables may be matched to the same EObject during evaluation. This behavior is called injectivity and can be demonstrated with the following example:
In this case, if the MyClass EClass has an attribute, then the query will have a match where Cls=MyClass and Cls2=MyClass.
If you want to explicitely declare, that two variables must always take on the same value, you can write:
Although in such cases you can just remove Cls2 and use Cls in each occurrence.
It is a more interesting case, when you declare, that two variables must never be the same. This can be written like this:
Query composition
It is possible to create query compositions, where a complex query only matches if other queries have matches with given parameters. This allows the separation of concerns in a complex query and even increases the performance of the evaluation if done correctly.
For example, the examples from the previous section can be implemented by reusing queries from earlier sections, e.g.:
It is important, that you can use the same variable in multiple find expressions, e.g.:
Negative application conditions
Finally, you can use negative application conditions (NAC), for indicating that if a given query matches with the given parameters, then the query containing the NAC must not match. For example:
Here, the MyClass EClass must not have any attributes, since that would mean a match for the negative application condition. Note that the Attr variable in the NAC is not used anywhere else in the query. In such cases, the Attr variable will not have a concrete value inside the query, as no positive constraints for its existence is given. For illustration, the following query is NOT equal to the previous one:
Note, that here, Attr must exist, but it must not be an eAttribute of Cls, since that would mean the NAC matches.
Non-existence of attributes
Unset or null-valued attributes (or references) simply won't match, as there is no referenced EObject or attribute value to substitute in the target pattern variable. If you are especially looking for these, use a negative application condition, e.g.:
Aggregation of match sets
In some cases, you may want to check that there is a given number of matches for a query and you are not interested what exactly the matches are. In these cases, you can use aggregation to assign the number of matches to a variable. For example, you can count the number of attributes for a class:
The result of count is always an Integer, so you can use it as a regular variable in other parts of the query, e.g. in a check:
More complex Ecore query example
For a more complex example on Ecore queries, see our dedicated example.
Integrating EMF-IncQuery into EMF-based Application
EMF-IncQuery Pattern Matcher API Documentation
Outdated content
The contents of this page have been superseded by the following page on the Eclipse Wiki:
http://wiki.eclipse.org/EMFIncQuery/UserDocumentation/API
Concepts
There are two ways you can use the EMF-IncQuery Pattern Matcher in your application. Either you can use the generic pattern matcher components, or the pattern-specific generated components. In most cases you won’t need the generic pattern matcher, which is much more complex to use. However they conform to the same reflective interfaces, and there is no performance difference between the two. Here we will present a simple introduction to the generated components, which contains many features to help you to integrate it into your java application.
Most important classes and relationships
For every pattern a Match, a Matcher, a MatcherFactory, a Processor and optionally several Evaluator classes are generated. Let’s look into what these classes are responsible for:
- Match: This represents a match of the pattern. Basically it is used to transfer data to and from the pattern matcher. The generated variables represent the pattern header parameters. You can use it to specify fixed input parameters to a query, and the results of you queries will be instances of this class. Note, that in each case the pattern parameters can be partially filled. It can be used in conjunction with the Matcher class.
- Matcher: This is the main entry point in our API, with pattern-specific query methods. First of all it provides means to initialize a pattern matcher for a given EMF instance model which can either be a Resource, a ResourceSet, or an EObject (in this latter case, the scope of the matching will be the containment tree under the passed EObject). We recommend the use of ResourceSets if possible to avoid cross-reference related issues. After the initialization of the engine the Matcher provides getter methods to retrieve the contents of the match set anytime. For easy iteration over the match set it provides a convenience method (forEachMatch) as well, as this is the most frequent use case in our observation. Of course it contains other handy features (e.g.: countMatches, hasMatch) to help integration. Finally, it provides a DeltaMonitor which can be used to track the changes in the match set in an efficient, event-driven fashion.
- MatcherFactory: A pattern-specific factory that can instantiate a Matcher class in a type-safe way. You can get an instance of it via the Matcher class’s factory() method. There are two ways to instantiate a Matcher, with a Notifier (e.g.: Resource, ResourceSet and EObject) as we mentioned already, or with an IncQueryEngine. In both cases if the pattern is already registered (with the same root in the case of the Notifier method) then only a lightweight reference is created which points to the existing engine.
- Processor: The Matcher provides a function to iterate over the match set and invoke the process() method of the IMatchProcessor interface with every match. To help with the processing an abstract processor class is generated, which you can override to implement the logic you would like to use. The abstract class unpacks the match variables so it can be used directly in the process() method.
- Evaluator: If your pattern contains check expressions an evaluator java code is generated from it. It is used by the engine during a query to evaluate the expression’s result. In most cases you don’t need to deal with these classes.
Lifecycle management
We have an EngineManager singleton class to orchestrate the lifecycle of the IncQueryEngines. There are two types of engines: managed and unmanaged. We recommend the use of managed engines, this is the default behavior, as these engines can share common indices and caches to save memory and cpu time. The EngineManager ensures that there will be no duplicated engine for the same root object. The managed engines can be disposed from the manager if needed. On the other hand creating an unmanaged engine will give you the power and responsibility to use it correctly. It will have no common part with other engines.
The IncQueryEngine is attached to an EMF resource (Resource, ResourceSet or EObject) and hosts the pattern matchers. It will listen on EMF update notifications stemming from the given model in order to maintain live results. Pattern matchers can be registered in the following ways:
- Instantiate the specific matcher class generated for the pattern, by passing to the constructor either this engine or the EMF model root.
- Use the matcher factory associated with the generated matcher class to achieve the same.
- Use the GenericPatternMatcher or the GenericMatcherFactory instead of the various generated classes.
If you want to remove the matchers from the engine you can call the wipe() method on it. It discards any pattern matcher caches and forgets the known patterns. The base index built directly on the underlying EMF model, however, is kept in memory to allow reuse when new pattern matchers are built. If you don’t want to use it anymore call the dispose() instead, to completely disconnect and dismantle the engine.
Typical programming patterns
We recommend trying out the @Handler annotation first, if you’re unfamiliar with the use of the EMF-IncQuery! It generates a sample code with a handler and a dialog that shows the matches of the query in a selected file resource. However you will only need to write just a few lines of code to start working with the pattern matcher:
Using the MatchProcessor
With the MatchProcessor you can iterate over the matches of a pattern quite easily:
Using the DeltaMonitor
There are some usecases where you don’t want to follow every change of a pattern’s match, just gather them together and process them when you’re ready. The DeltaMonitor can do this for you in a convenient way. It is a monitoring object that connects to the rete network as a receiver to reflect changes since an arbitrary state acknowledged by the client.
If a new matching is found, it appears in the matchFoundEvents collection, and disappears when that particular matching cannot be found anymore. If the event of finding a match has been processed by the client, it can be removed manually. In this case, when a previously found matching is lost, the Tuple will appear in the matchLostEvents collection, and disappear upon finding the same matching again. "Matching lost" events can also be acknowledged by removing a Tuple from the collection. If the matching is found once again, it will return to matchFoundEvents.
EMF IncQuery Databinding Documentation
Outdated content
The contents of this page have been superseded by the following page on the Eclipse Wiki:
http://wiki.eclipse.org/EMFIncQuery/UserDocumentation/Databinding
Data binding overview
Data binding [1] is general technique that binds two data/information sources together and maintains synchronization of data. In UI data binding data objects are bound to UI elements and if the binding is done in the proper manner the changes in the data will be automatically reflected on the UI elements (for example a label will be automatically refreshed with new contents).
EMF-IncQuery provides a simple data binding facility that can be used to bind pattern match parameters to UI elements. The feature is mainly intended to be used to integrate EMF-IncQuery queries to newly developed user interfaces, however, the Query Explorer component also uses some related annotations
The scope of this document
This document is intended to be used mainly by developers but the section dealing with data binding related annotations may be useful for EMF-IncQuery end-users too.
Data binding related annotations
The following annotation can be used on patterns within the data binding context:
- @QueryExplorer: the message parameter of the Query explorer annotation defines the label feature of the selected match.
-
@ObservableValue: allows the developer to customize the appearance of a match inside the Details panel. It defines an observable value (as defined in JFace databinding) which can be bound to an Eclipse/JFace UI. This annotation will also trigger the generation of an additional .databinding side-project next to your EMF-IncQuery project, which includes some helper classes that you can use to ease the integration of EMF-IncQuery into your user interface.
-
Annotation parameter(s):
- name (String): the name of the parameter
- expression (String): the attribute definition without '$' marks. For example @ObservableValue(name = "Year", expression="Y.startingDate")
- The parameters of the pattern are considered the default observable values of the matcher. This means, it is not required to present values like @ObservableValue(name="Y" expression="Y"). However, it is possible to redefine these values by simply defining a new value, e.g. @ObservableValue(name="Y" expression="Y.startingDate").
- It is possible to use the annotation without parameters: in this case, it only represents that a default Observable matcher object should be generated with the default observable values.
-
Annotation parameter(s):
The following example is from the school tutorial (see link on the bottom of this page under the 'Examples' section). Here, a pattern is given with various annotations.
The @QueryExplorer annotation will result that the match of the finalPattern (it has at most one match) pattern will have a label with the form of 'The busiest teacher $T.name$ taught the most sociable student $S.name$ in $Y.startingDate$' inside the Query Explorer. The attribute markers will be replaced with the appropriate attribute values based on the current pattern match.
For a more specific example on the @ObservableValue annotation see the next section.
Generated data binding plug-in
The .databinding side-project will only be generated if at least one pattern is annotated with @ObservableValue in your EMF-IncQuery project. In this case a $PatterName$DatabindingAdapter.java class will be generated which is a subclass of DatabindingAdapter.
In the finalPattern context mentioned above, the three @ObservableValue annotations will result that a FinalPatternDatabindingAdapter class will be generated in a .databinding side-project. The getParameterNames method call will return the array of ["Year","Teacher","Student"]. For each of these parameters an IObservableValue can be obtained based on the given attribute expression and a specific match of the pattern.
Please note that if you are binding an IObservableValue instance obtained from the above mentioned class, it is important to pay attention on the binding's update strategy as you should not use a two-way updating strategy (because it would modify the pattern match parameter). For example if you use an org.eclipse.core.databinding.DatabindingContext instance's bindValue method to create the binding, the suggested UpdateValueStrategy is the following:
- UpdateValueStrategy.POLICY_NEVER in the UI to pattern match parameter binding
- UpdateValueStrategy.POLICY_UPDATE in the pattern match parameter to UI binding
Also worth noting that you must take care of the IObservableValue instances' life-cycle as the pattern match may be removed from the match set of the EMF-IncQuery matcher. The best way to receive notification about the match disappearance is to register a listener on the matcher and upon callback, process the delta monitor's matchFoundEvents and matchLostEvents.
Example and useful resources
- Please see the school example (https://viatra.inf.mit.bme.hu/incquery/new/examples/school) which demonstrates the usage of the above mentioned annotations.
- The following tutorial is an in depth document about JFace/SWT data binding: http://www.vogella.com/articles/EclipseDataBinding/article.html
- The org.eclipse.viatra2.emf.incquery.tooling.gui/src/org/eclipse/viatra2/emf/incquery/queryexplorer/content/detail/DetailObserver.java gives a hint how the generated data binding code can be used (in this case for the Query Explorer's Details view).
DetailObserver.java highlights
The DetailObserver class extends the AbstractObservableList class, thus can be used in data binding contexts. Within the EMF-IncQuery project it is used to server as the input for a TableViewer which diplays pattern match details. The TableViewer's content provider is ObservableListContentProvider, this way data binding is automatically created and maintained.
The cunstuctor initializes the data structures and registers the IValueChangleListener instance on all pattern match parameters which were declared with an @ObservableValue annotation, thus having a getter for its observable value in the appropriate DatabindingAdapter subclass.
The addDetail and removeDetail methods modifiy the contents inside the view and notify (with the fireListChange call) the UI element that the backing content has changed.
We have registered the IValueChangeListener instance on all pattern match parameters in the constructor. Upon attribute modification this listener will be called and the appropriate element can be changed in the details view.
[1] Data binding on wikipedia (http://en.wikipedia.org/wiki/Data_binding)
EMF-IncQuery Validation Framework Documentation
Validation framework overview
EMF-IncQuery provides facilities to create validation rules based on the pattern language of the framework.
These rules can be evaluated on various EMF instance models and upon violations of constraints, markers are automatically created in the Eclipse Problems View.
Example use case
The following scenario describes and illustrates the way to use the framework for validation purposes (see also the BPMN example):
- Create an EMF-Incuery project with some patterns
-
Annotate some pattern with the @Constraint annotation - these will be the constraints. In particular, these patterns will be treated as queries that find the violations of the contraint.
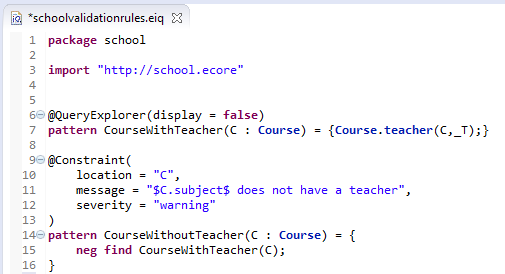
- Add the generated .validation project to your run configuration (along with the base EMF-IncQuery plug-in)
-
Initialize the validation framework on some instance model; use the UI context menu on an EMF editor to do so.
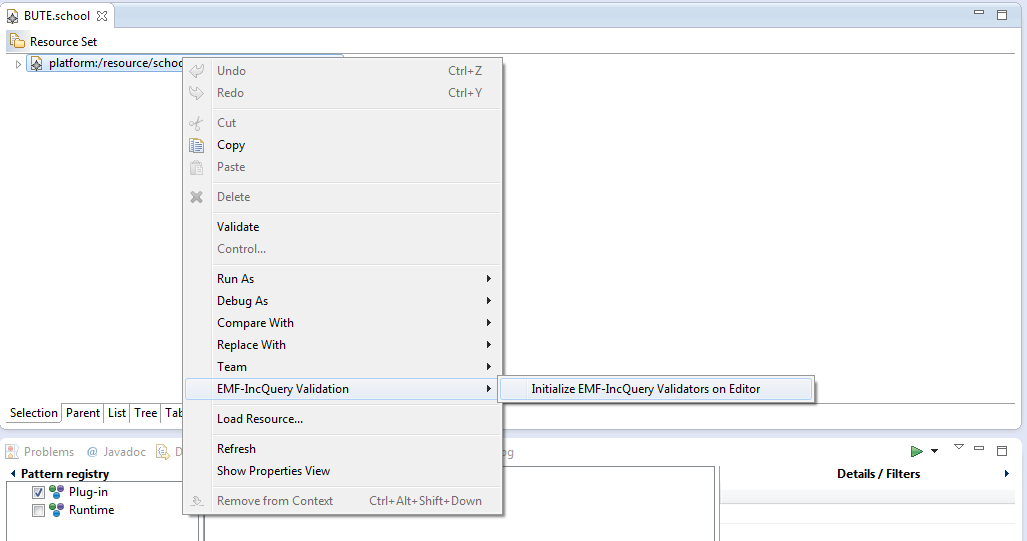
-
Upon constraint violation markers will be placed in the Problems view. Note that the markers are data-bound to corresponding model elements and the labels will be automatically refreshed (when the model changes).

Annotations
The @Constraint annotation can be used to mark an eiq pattern as a validation rule. If the framework finds at least one pattern with such annotation, an additional .validation project will be generated. This project will be used by the validation framework later in your runtime Eclipse configuration.
Annotation parameters:
- location: The location of constraint represents the pattern parameter (the object) the constraint violation needs to be attached to.
- message: The message to display when the constraint violation is found. The message may refer the parameter variables between $ symbols, or their EMF features, such as in $Param1.name$.
- severity: "warning" or "error"
- targetEditorId: An Eclipse editor ID where the validation framework should register itself to the context menu. Use "*" as a wildcard if the constraint should be used always when validation is started.
Generated validation plug-in
The generated .validation project will create a subclass of org.eclipse.viatra2.emf.incquery.validation.runtime.Constraint for each one of the patterns annotated with @Constraint.
Example and useful resources
- Please see the BPMN example which demonstrates the usage of the @Constraint annotation.
- The org.eclipse.viatra2.emf.incquery.validation.runtime.ConstraintAdapter.java and org.eclipse.viatra2.emf.incquery.validation.runtime.ConstraintViolation.java classes demonstrate the usage of the generated validation code inside the validation framework.
ConstraintAdapter and ConstraintViolation highlights
The validation framework collects all of the Constraints that applies to the constraint extension point schema (defined under org.eclipse.viatra2.emf.incquery.validation.runtime/schema/constraint.exsd). These constraints are initialized on the loaded instance models and upon constraint violation an appropriate error marker is placed in the runtime Eclipse's Problems View.
First for each collected constraint and instance model a ConstraintAdapter is created which will maintain the match set of the pattern (annotated with @Constraint); these matches are constraint violations, that the user needs to be informed about. For each match of the pattern a ConstraintViolation is instantiated, which is responsible for marker creation/update/deletion.
The ConstraintViolation class uses data binding facilities to register the appropriate callback methods on the location objects of the Constraint, this will result in marker text update when an attribute of some location object is modified.
EMF IncQuery Query-based Structural Features Documentation
EMF-IncQuery supports the definition of efficient, incrementally maintained, well-behaving derived features in EMF by using advanced model queries and incremental evaluation for calculating the value of derived features and providing automated code generation for integrating into existing applications.
Main scope of query-based features
- Integrate model query results into EMF applications as structural features
- Replace low performance derived feature implementations with incrementally evaluated model queries
- Provide a flexible interlinking method for fragmented models
- Support declarative definition of high-performance computed features with automatic code generation and validation
Overview
Derived features in EMF models represent information (attribute values, references) computed from the rest of the model, such as the number of elements in a given collection or the set of elements satisfying some additional conditions. Such derived features can ease the handling of models significantly, as they appear in the same way as regular features. However, in order to achieve complete transparency for derived features, the developer must ensure that proper change notifications are sent when model modifications cause changes in the value of the derived feature as well. Finally, since the value of the derived feature might be retrieved often, complete recalculation of the value may impact application performance. Therefore, it is better to keep a cached version of the value and update it incrementally based on changes in the model.
Usually, developers who use derived features in EMF have to manually solve each of these challenges for each derived feature they introduce into their model. Furthermore, although the derived features almost always represent the result of a model query (including type constraints, navigation, aggregation), they are implemented as imperative Java code.
In order to help developers in using derived features, EMF-IncQuery supports the definition of model queries that provide the results for the derived feature value calculation and includes out-of-the-box change notification and incremental maintenance of results. Additionally, the automatic generation of the glue code between the EMF model code and EMF-IncQuery offers easy integration into any existing EMF application.
Well-behaving structural features
The incremental approach of EMF-IncQuery relies on change notifications from every object and every feature in the model that is used in the query definitions. Therefore, a regular volatile feature that has no field, therefore there it does not store the current value of the feature and usually does not send proper change notifications (e.g. SET oldValue to newValue ). Such features are ignored by EMF-IncQuery, unless there is an explicit declaration, that the feature implementation sends proper change notifications at all times. These are called well-behaving structural features.
If your application uses volatile (and often derived) features, you provide proper notifications for them and would like to include them in query definitions, you can explicitly tell EMF-IncQuery that the feature is well-behaving. There is two ways to do this:
- extend the org.eclipse.viatra2.emf.incquery.base.wellbehaving.derived.features extension point as described here
- register your feature directly into the org.eclipse.viatra2.emf.incquery.base.comprehension.WellbehavingDerivedFeatureRegistry using the various registerX methods. Note that you must call this method before executing any queries (i.e. before the first getMatcher() or getEngine() call), since EMF-IncQuery checks the registry when it traverses the model.
Examples
For demonstration, we will use the school metamodel from the introductory example:
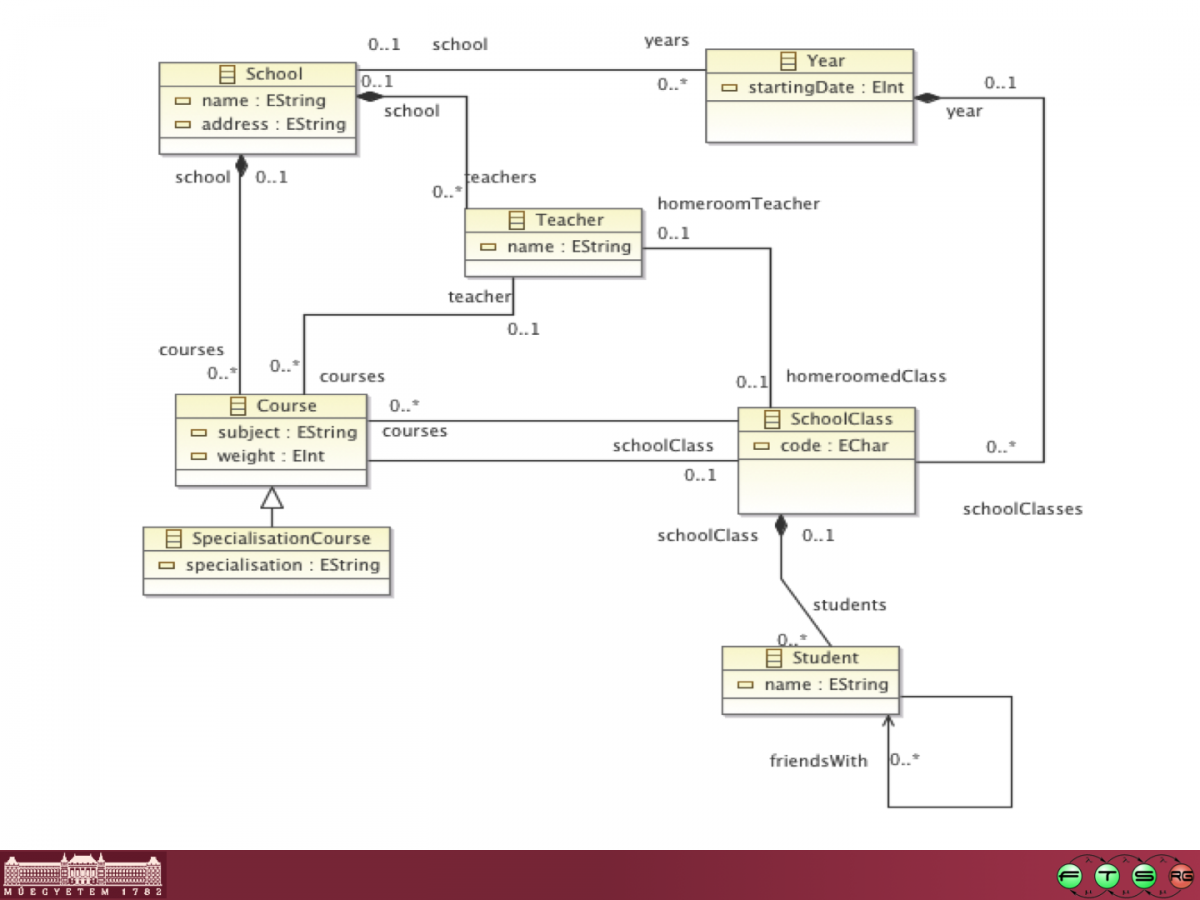
Example derived features in this metamodel could be the following:
- Students enrolled in a given course: this feature would return the list of Students reached with the students reference from the SchoolClass that is connected by the schoolClass reference to the Course.
- Number of specialization courses: this feature would count the number of SpecializationCourse objects in the courses reference of a given School.
Other examples
You can find examples using the EMF-IncQuery based derived features in the following locations:
Simple school example enhanced with derived features
Soft interconnections between models in different resources
Furthermore, we use such derived features in the snapshot models that are used for serializing result sets of EMF-IncQuery matchers.
How to use
EMF-IncQuery only provides the back-end for derived features, the developer must define the feature itself in the metamodel first. Once that is complete, the developer creates the query in a regular EMF-IncQuery project in a query definition file and adds a specific annotation with the correct parameters to invoke the code generation. These steps are detailed in the following:
-
Definition of the derived feature:
- In the Ecore model (.ecore file), create the desired EAttribute or EReference in the selected EClass and set the name, type and multiplicity information correctly.
- Use the following configuration for the other attributes of the created EStructuralFeature:
- derived = true (to indicate that the value of the feature is computed from the model)
- changeable = false (to remove setter methods)
- transient = true (to avoid persisting the value into file)
- volatile = true (to remove the field declaration in the object)
- In the Generator model (.genmodel), right-click on the top-level element and select Reload, click Next, Load, and Finish to update the Generator model with the changes done in the Ecore model.
- Right-click on the top-level element and select Generate Model Code to ensure that the getters are properly generated into the EMF model code. You can regenerate the Edit and Editor code as well, though those are not necessary here.
-
Definition of the model query:
- Create an EMF-IncQuery project and query definition (.eiq) file as described in the cheat sheet or this tutorial.
- Make sure that you imported your metamodel into the query definition. Create the EMF-IncQuery generator model, if necessary (.eiqgen file).
- Make sure that the project containing the generated code is in the same workspace as the EMF-IncQuery project.
-
Create the query corresponding to your derived feature. For example, the students enrolled in a given course feature would look like this:
Note that the first parameter of the pattern is the source of the derived feature and the second is the target. Although not mandatory, is is good practice to use the (This : EClass, Target) format to ease understanding. The @QueryBasedFeature annotation indicates to the code generator that the glue code has to be generated in the model code.
- Save the query definition, which initiates the code generation. After it completes, you can open the implementation code to ensure that the new getter method is correctly created. Note that a well-behaving derived feature extension is also generated into the plugin.xml of the EMF-IncQuery project to indicate that the given derived feature correctly sends change notifications if the correct project is loaded.
-
Running the application:
- Once the glue code is generated, you can use the derived features by including the EMF-IncQuery project into your runtime together with the model project.
Annotation parameters
The @QueryBasedFeatureannotation uses defaults for each possible parameters, which allows developers to avoid using any parameters if the query is correctly written.
In short, parameters are not needed, if the following conditions are satisfied:
- The name of the pattern is the same as the name of the derived feature (comparison uses String.equals())
- The first parameter is the defining EClass and its type is correctly given (e.g. This : Course)
- The second parameter is the target of the derived feature
- The derived feature value is a single EObject or a collection of EObjects
If the derived feature and its query does not satisfy the above conditions, the following parameters can be used in the annotation:
- feature ="featureName" (default: pattern name) - indicates which derived feature is defined by the pattern
- source ="Src" (default: first parameter) - indicates which query parameter (using its name) is the source EObject, the inferred type of this parameter indicates which EClass generated code has to be modified
- target ="Trg" (default: second parameter) - indicates which query parameter (using its name) is the target of the derived feature
- kind ="single/many/counter/sum/iteration" (default: feature.isMany?many:single) - indicates what kind of calculation should be done on the query results to map them to derived feature values
- keepCache ="true/false" (default: true) - indicates whether a separate cache should be kept with the current value. Single and Many kind derived features can work without keeping an additional cache, as the EMF-IncQuery RETE network already keeps a cache of the current values.
Developer documentation
The JavaDoc can be found here.
Overview of the implementation
To support query-backed features captured as derived features, the outputs of the EMF-IncQuery engine need to be integrated into the EMF model access layer at two points: (1) query results are provided in the getter functions of derived features, and (2) query result deltas are processed to generate EMF Notification objects that are passed through the standard EMF API so that application code can process them transparently.
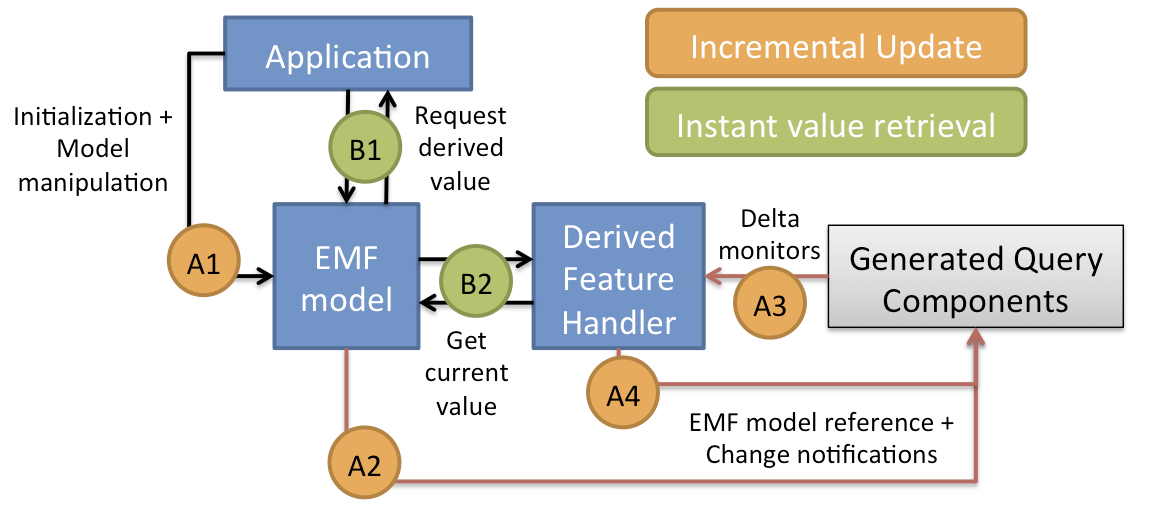
Instantiating query-based feature handlers
The easiest way is to create a simple query-based feature and look at the generated code in the getter function.
If you need to create a handler for some reason, use the static getQueryBasedFeatureHandler() methods of the QueryBasedFeatureHelper class.
Example codes that were generated for the school example:
Accessing the current value of query-based features
The most straightforward way is to call the getter method of the feature itself. However, if for some reason that is not possible, you can access the values using the getter methods of the QueryBasedFeatureHandler object. Apart from the generic getValue, there are specific methods (getIntValue, getSingleReferenceValue etc.), each returning a properly typed target for a given source element.
Advanced issues
Creating an iteration query-based feature
It is possible to create a query-based feature that is not simply the result of the model query, but the value calculated by an iteration algorithm on the results of the query.
Important: the iteration algorithm must be able to compute the new value based on it's current value and the new or lost match of the used query.
In order to create your own iteration feature, you need to subclass QueryBasedFeature and implement the following methods:
- newMatchIteration(IPatternMatch): based on the match (that just appeared) passed to the method, return a notification that represents the changes in the value of the feature. Note that you should not send out this notification, that is the responsibility of the feature handler.
- lostMatchIteration(IPatternMatch): based on the match (that just disappeared) passed to the method, return a notification that represents the changes in the value of the feature. Note that you should not send out this notification, that is the responsibility of the feature handler.
- getValueIteration(Object): based on the source element passed to the method, return the value for the feature.
Pitfalls
Code generation fails for derived feature query
Ensure that both the .genmodel file and the model project with the generated EMF model code is available in the same workspace as the EMF-IncQuery project with the query definitions.
Multiple results for a query used in a single (upper bound = 1) feature
If you define a query for a single feature that returns multiple results for a given source model element, the value of the derived feature will in most cases be the value from the last match that appeared. However, it is possible to change the values in a way that the feature will have no value, even though it might have exactly one. Therefore, it is important to define the queries for the feature in a way that only one result is possible. You can either make assumptions on your models and use other ways to ensure that there is only one match, or you can explicitly declare in the pattern, that it should only match once for a given source element. Additionally, you can use the Validation framework of EMF-IncQuery to create feedback for the user when the query would have multiple results indicating that the model is invalid.
The following is an example for a validated, ensured single feature:
UnsupportedOperationException during model editing, even after successful generation
If you have multiple inheritance in your metamodel, it is possible that the getter for a feature will be implemented in more than one place. The easy way to avoid this is to ensure, that query-based features are only inherited from one supertype and that supertype is used as the extension and not only as interface (i.e. that type must be the first in the values of the supertypes feature).
In the unfortunate case when you have query-based features in multiple supertypes, the generator will only override the getter in the implementation class of the defining EClass, so you will have to copy-paste the generated getter code and the handler into the subclass implementation as well.
Future versions of EMF-IncQuery may support the automatic generation into multiple implementation classes.
EMF-IncQuery Examples and Demos
The examples below correspond to updated versions of the old examples.
Introductory example: school
The school example features a simple EMF model and some simple graph patterns to show the very basics of using EMF-IncQuery. Read this first before anything else!
Introductory example: BPMN validation
The BPMN validation example introduces the IncQuery Validation Engine, by which incrementally evaluated, on-the-fly well-formedness validation rules can be specified for any EMF model.
Metamodel pattern matching example: ECore Queries
Have you ever tried to query a meta-model, i.e. a model consisting of EClasses, EAttributes, and EReferences, against a meta-model pattern? For an example, look here. In this case, we want to look for a certain sub-configuration in an ECore metamodel, where two EClasses (each having an EAttribute of type EString) are connected by a 0-* EReference.
Use-cases of this technique include meta-transformation, meta-model analysis, higher-order transformations where transformation rules are generated/parameterized by metamodel analysis etc.
Using queries for derived features
We demonstrate how our high performance queries can be easily integrated with other EMF tools using an entirely new case study in which EMF-IncQuery is deeply integrated into the EMF modeling infrastructure to facilitate the incremental evaluation of derived EAttributes and EReferences.
Running IncQuery as a headless RCP application
IncQuery can be called without any graphical user interface or even a complete Eclipse installation. In this example we take an existing IncQuery project and create an Eclipse Application that can be executed from a console (command prompt) to print the matches for an arbitrary input model file.
Query-driven soft interconnections of EMF models
We demonstrate how the incremental query evaluation of EMF-IncQuery can be used to maintain soft interconnections between EMF models stored even if they are stored separately, moved or modified without the all the corresponding models loaded at all times.
Real-time gesture recognition with Jnect and the Esper CEP engine
This demo was prepared for EclipseCon Europe 2012. Using live input from Jnect, the body model of a human user is processed by EMF-IncQuery in real time to recognize gestures. Additionally, the Esper Complex Event Processor is integrated into the system to allow the recognition of gesture sequences in the event stream generated by IncQuery.
Introductory example: School
Overview
The aim of this page is to provide an easy-to-understand, step-by-step guide to EMF-IncQuery. For this purpose, the school example features a simple EMF model and some simple graph patterns to show the very basics of the query language and the core add-ons.
Obtaining the example
In the simple case, you can install the School example from the IncQuery Extra update site.
Alternatively (for advanced users): you will need two Eclipse workspaces to try this example.
- In your host Eclipse workspace, check out the school EMF projects from Github:
- In your runtime Eclipse workspace, check out the example project and some sample instance models from Github:
You can launch the (school, school.edit, school.editor) projects in a Runtime Eclipse application (which will use the runtime workspace), or you can install them into your host Eclipse (in that case, no separate runtime workspace is necessary).
Source projects
- host workspace / installed plugins: school, school.edit, school.editor
The school project contains the EMF metamodel (school.ecore) for representing schools, years, classes, students, teachers, and courses. The .edit and .editor projects are automatically generated by EMF (no manual tweaking on the school.genmodel was performed.)
Example query and instance model contents
- runtime workspace: school.instancemodel/
This project contains two school instance models with a school, years, classes, students, teachers, and courses.
You can create your own model using the standard generated EMF features: New/Other/Example EMF Model Creation Wizards/School Model.
BUTE.school contains the following configuration (some details, such as attribute values, have been omitted for the sake of clarity):
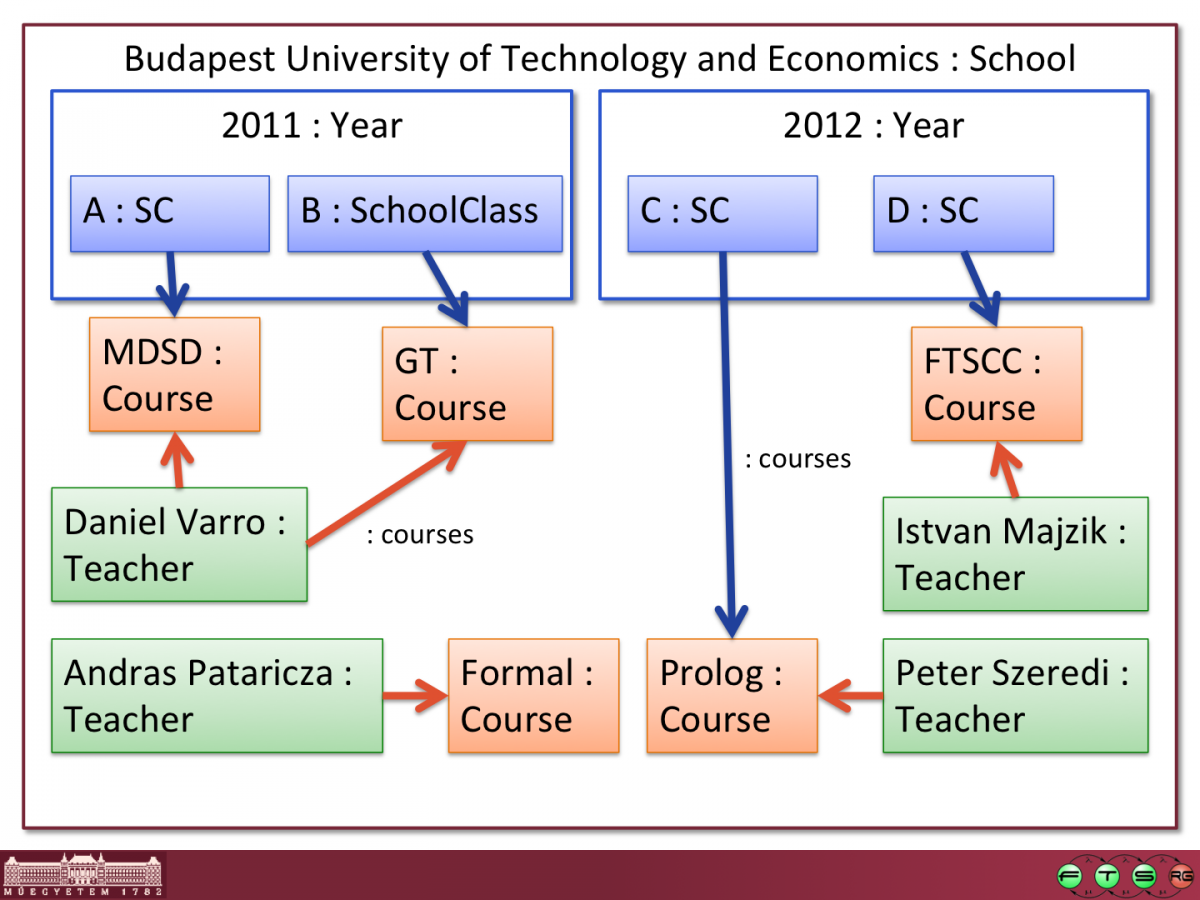
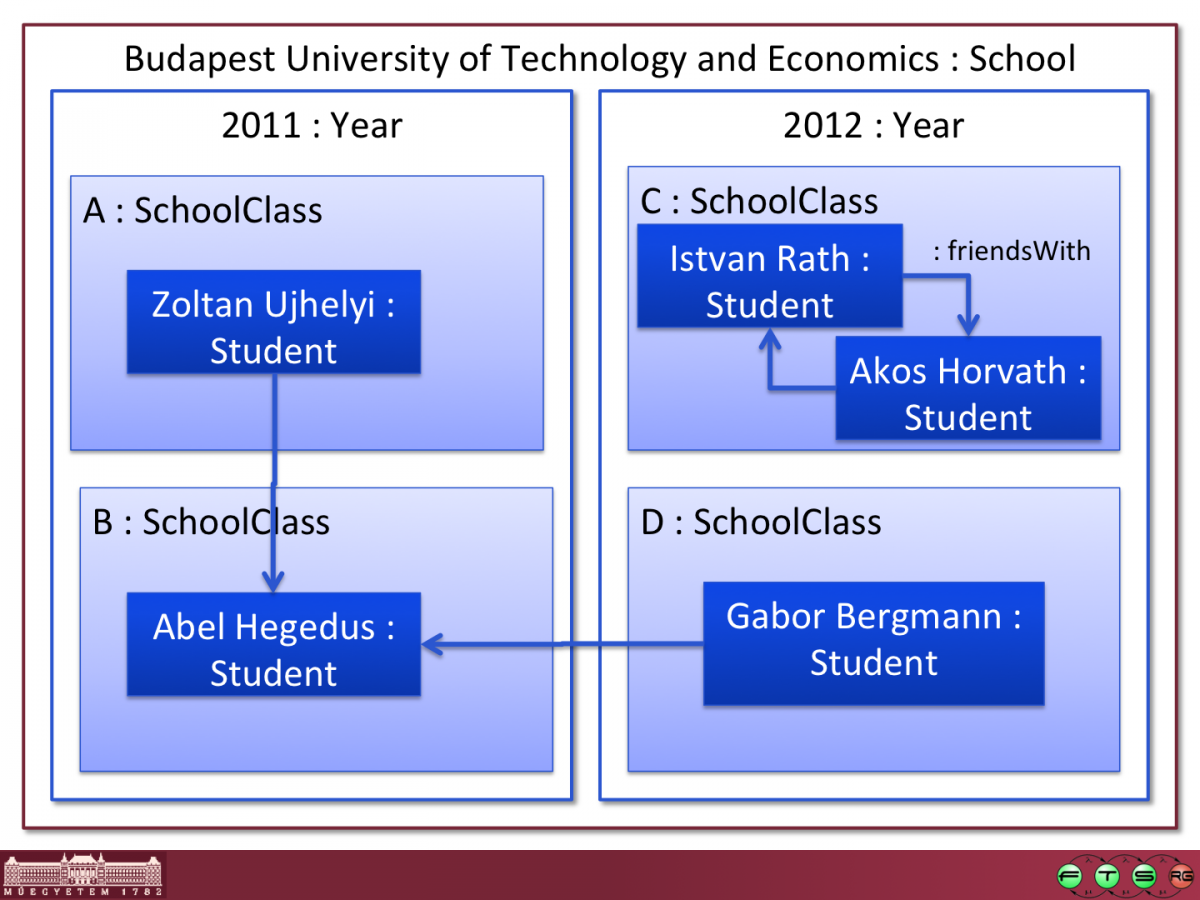
Hogwarts.school is another simple instance model example, borrowing some characters from a famous novel.
- runtime workspace: school.incquery/
This project is an EMF-IncQuery Project (created with New/Other/EMF-IncQuery/EMF-IncQuery Project). It also contains the tutorial queries (patterns) in the src/school/schoolqueries.eiq file, which has been created using the New/Other/EMF-IncQuery/EMF-IncQuery Query Definition wizard.
Jump right in - try the patterns!
- Make sure you are in the runtime workspace.
- Make sure the "Query Explorer" view of EMF-IncQuery is open (Window/Show view/EMF-IncQuery/Query Explorer).
- In the school.incquery project, right click in the schoolqueries.eiq file and choose EMF-IncQuery/Register patterns in Query Explorer.
Alternatively, you can use the magical green button of the Query Explorer view (green triangle in the view toolbar) when the schoolqueries.eiq file is the active editor. - Observe that the patterns have been registered by opening the left-side panel (Pattern registry) of the Query Explorer.
- Open BUTE.school file (either with the generated School editor, or the Sample Reflective Ecore model editor, both of them should work).
- Import the instance model into the Query Explorer by using the magical green button again (while the instance model editor is the active editor).
- Observe that the instance model has been loaded; expand the tree to see each pattern and their matches.
You should see something like this:
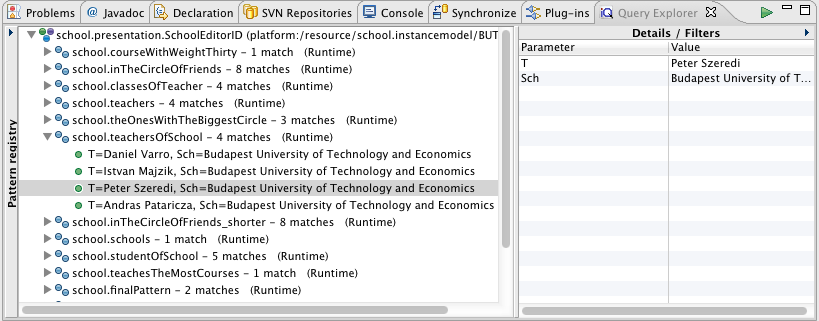
Observe that both the Pattern Registry and the Details/Filters panels can be toggled, depending on whether you prefer to see their contents or not. The Details/Filters panel is also useful for parameterized (parameter-bound) queries (see later). If you double-click on a match (green dot icons), the selection corresponding to the match (containing all model elements referenced by pattern parameters) will be applied to the host editor (revealing the corresponding model elements automatically). This is useful if you want to locate the model elements in the editor.
Detailed step-by-step guide
Now we describe step-by-step how the sample queries/patterns have been created and what they do. The 7-step tutorial is intended to serve as a quick overview of the language and tooling features. To ease understanding, it is always a good idea to check the language overview and the FAQ. For performance considerations, be sure to check the performance guide.
Step 0 - header
When you first create an IncQuery query definition, an empty file will be created, with only a package declaration. The package declaration is primarily used to determine the Java packages of the code that IncQuery will generate.
In order to start working with IncQuery, you need to import an Ecore namespace, by typing the import keyword and then activating content assist (ctrl-space) and selecting a registered EPackage. Just after you have entered an import declaration, it is a good idea to include an appropriate plugin dependency to the contributing EMF .model plugin (in this case, school) in the MANIFEST.MF of the IncQuery project, and also take care to re-export this dependency.
Workspace EPackages will be usable with the EMF-IncQuery Generator Model (generator.eiqgen) by pointing to the genmodel file of the used metamodels. Once you add the resource URI to the eiqgen file, you can import with the nsUri in the eiq file.
Step 1 - simple queries
The most simple queries in IncQuery are graph patterns that identify nodes and edges of the EMF instance model.
- nodes (EObjects) can be identified by their Ecore types, such as School or Teacher. A simple pattern consisting of a single node type constraint will yield all instances of that type in the query results, called match set in IncQuery terminology.
- edges (EReference "instances", i.e. Java references) can be added as additional structural constraints by their Ecore types, such as School.teachers.
- in the teachersOfSchool pattern above, we are looking for pairs of School-Teacher instances that are actually connected by a teachers edge.
- Notice that IncQuery has type inference: as the types of the edges endpoints can be inferred from the metamodel, there is no need to include additional Teacher(T) and School(Sch) constraints. The types are defined in the pattern header only for the sake of end-user readability.
- Notice that IncQuery implicitly makes all EReference navigation bidirectional: while you have to formulate the pattern in a syntactially correct way (specifying that the teachers edge is defined for the School EClass), the query evaluates all connected School-Teacher pairs and thus can be used to look for the Schools belonging to a particular Teacher instance (thus navigating backward along the teachers edge). This works regardless whether there is an EOpposite relationship defined or not.
Step 2 - pattern calls, negative application conditions
One of the most powerful reusability features of the IncQuery pattern language is the find keyword. You can use it to call patterns from other patterns, giving you the ability to factor out commonly used code segments and reuse them whereever necessary. The find keyword uses an intuitive parameter passing semantics, identifying (bound) objects by the parameter they are assigned to (i.e., in the example, wherever you write C, it means the same object).
The find keyword can be preceded by the neg modifier to invert the meaning, i.e. forbid the match of the called pattern with the given parameterization. In that case, unbound parameters (SC) will be "running parameters", i.e. they are not allowed to be matched by anything.
Step 3 - path expressions
Path expressions are useful to compacting patterns, wherever intermediate nodes along a path are not important. Notice that in this particular case, the direction of navigation is unimportant in the sense that both ways of connecting S and Sch yield the same result, because all the included EReferences have EOpposites.
Step 4 - check conditions
Check expressions are useful for specifying value constraints, most frequently for EAttributes. Technically, you write Xbase into a check() expression, making it possible to include complex (imperative) logic right inside the query definition.
- For the limitations on check() expressions, see the language reference
- 0.6 limitation: the basic rule of thumb is that you should never include navigation inside a check expression; only write (side effect free) code that accesses a single object from the pattern body and make sure your expression returns a boolean value in a deterministic and idempotent way (that is, the same value for the same input, independently of when it is invoked). Some of these limitations will be lifted for v0.7+.
- 0.6 limitation: once IncQuery will have full type inference, the type casts (as) inside check() expressions will not be necessary.
- For details on Xbase expressions, see the Xbase reference
Step 5 - counting
Counting can be used to refer to the size of the match set inside a query. This comes handy e.g. when you want to identify the model element with the minimum/maximum of something. Similarly to neg, cound find involves (a) running (unbound) variable(s) that act(s) as the objects (that)/(whose combinations) will be counted.
Step 6 - disjunction, transitive closure
By default, all clauses inside the pattern body are interpreted as a conjunction (i.e. AND). IncQuery also supports disjunction by OR patterns, whereby multiple pattern bodies can be assigned.
IncQuery includes a specific language construct to define transitive closures, i.e. the computation of reachability relationships where a single step is defined by a (binary) pattern (friendlyTo in the example). This construct is supported by a much more efficient evaluation back-end (evaluated for a recent ICGT conference paper). In order to try the transitive closure, we suggest you to edit the students inside the model, add/remove friendsWith relationships and observe how the match set of the inTheCircleOfFriends patterns change!
Step 7 - combining everything
In the final step of the walkthrough, we combine the previously defined patterns to define a multi-parameter query. It is important to note that in IncQuery, patterns can have an arbitrary number of parameters, any of which can be bound/unbound freely. The Query Explorer supports parameterized queries (parameter binding) through the Details/Filters panel on the right: by selecting a pattern in the tree, you have the ability to specify Filters for each parameter separately.
- as pattern parameters can be scalars, such values can be entered by typing the string value or number, boolean literal etc.
- object pattern parameters can be specified by the model element picker cell editor.
The finalPattern example is intended to highlight the most important advantage of the IncQuery pattern language over other (EMF) query languages: it has been designed to make the specification of complex graph queries involving multiple objects and inter-relationships compact and easy-to-understand.
This example also demonstrates the usage of IncQuery add-ons by query annotations:
- @PatternUI allows the developer to customize the appearance of a pattern match in the Query Explorer tree. Inside the message, simple path expressions (only allowing direct EAttribute access) can be used inside $$ sections to include match-specific details.
- @ObservableValue allows the developer to customize the appearance of a match inside the Details panel. It defines an observable value (in the JFace databinding sense) which can be bound to an Eclipse/JFace UI. This annotation will also trigger the generation of an additional .databinding side-project next to your IncQuery project, which includes some helper glue code that you can use to ease the integration of IncQuery into your application.
- @Handler triggers the generation of a .ui side-project that contains a command handler class that can be used on instance model files inside e.g. the Package Explorer view (invokable from the right-click context menu, under the EMF-IncQuery submenu). The contents of this class illustrate the usage of the pattern matcher interface code that is generated by IncQuery inside your IncQuery project (inside the src-gen folder). This interface is used to invoke queries from Java code, and they are designed to make the integration of IncQuery features into any EMF application easy and straightforward.
Another annotation add-on, @Constraint (which is used to specify IncQuery-based well-formedness rules) is discussed in a separate example page: BPMN Validation.
Generated code overview
Outdated content
The contents of this section have been superseded by the following page on the Eclipse Wiki:
http://wiki.eclipse.org/EMFIncQuery/UserDocumentation/API
We now briefly overview the source code generated by the IncQuery generator (inside the src-gen folder of your IncQuery project). This is not meant to be a very detailed description; it is recommended to check the code yourself for specific details and useful tidbits not discussed here.
Match and Matcher
The two most important components of the IncQuery Java integration interface are the _Match and _Matcher classes:
- The _Match class represents a data transfer object, corresponding to a single match of your pattern. It is basically a tuple of objects that are identified by the header parameters of the pattern.
- The _Matcher class is the main accessor interface to IncQuery's pattern matching engine:
- it provides means to initialize a pattern matcher for a given EMF instance model (which can either be a Resource, a ResourceSet, or an EObject -- in this latter case, the scope of the matching will be the containment tree under the passed EObject).
- it provides getter methods to retrieve the contents of the match set anytime.
- it provides a convenience method (forEachMatch) for easy iteration over the match set -- the most frequent usecase.
- finally, it provides a DeltaMonitor which can be used to track the changes in the match set in an efficient, event-driven fashion.
Using the Matcher
This example illustrates the most basic usage of the IncQuery API. In fact, this code is generated by the @Handler annotation add-on, and shows how to programmatically load and EMF instance model, initialize a matcher for it, and retrieve/process the results.
Introductory example: BPMN validation
Overview
The aim of this example is two-fold:
- to demonstrate how well-formedness (validation) rules can be easily specified using EMF-IncQuery;
- to demonstrate the generic integration capabilities of the IncQuery framework; that is, the ability to work with almost any EMF-based tool out-of-the-box, without having to touch the source code of the original tool.
It is a good idea to check the School example walkthrough before reading this page.
Prerequisites
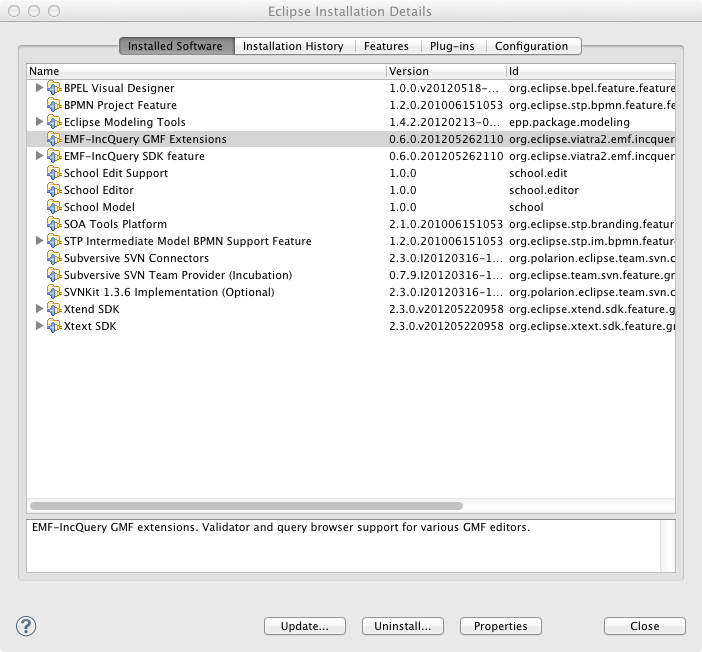
- A recent version of EMF-IncQuery v0.6, make sure to also install the "GMF Extensions".
- The BPMN Modeler from the Eclipse SOA Tools Platform project: http://www.eclipse.org/projects/project.php?id=soa.bpmnmodeler
A working configuration may look like this (note that there are other features installed here which are not strictly necessary for this example):
Getting the example
Download the IncQuery project and some sample instance models from github:
- https://github.com/ujhelyiz/EMF-IncQuery-Examples/tree/master/bpmn/bpmn.incquery
- https://github.com/ujhelyiz/EMF-IncQuery-Examples/tree/master/bpmn/bpmn.instancemodel
Make sure to build the bpmn.incquery project to ensure that the bpmn.incquery.validation auxiliary project is generated and compile error free.
Trying the example
- Run the bpmn.incquery and bpmn.incquery.validation projects in a runtime Eclipse Application.
- Open the bpmn.instancemodel/default.bpmn_diagram in the newly launched Eclipse.
- Activate the context menu inside the diagram editor, select Initialize EMF-IncQuery Validators.
- Make sure the Problems view is open. It should look as follows:
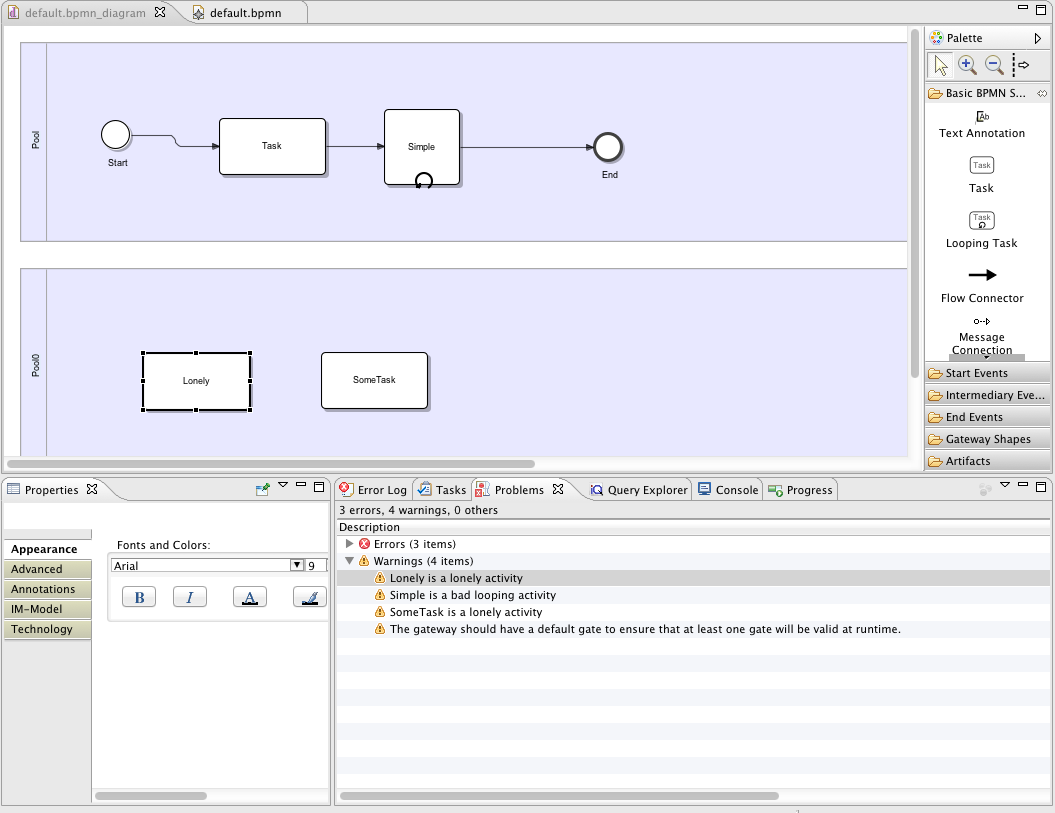
If you now insert a new Flow connector edge between "Lonely" and "SomeTask", the warning markers will be automatically removed on-the-fly by the IncQuery Validation Engine. Similarly, if you rename the "Simple" looping activity to "Looping activity", the "bad looping activity" marker will disappear.
- You can try editing the model and observing how the validation status will change (hint: take a look at the sample code below, and check the two well-formedness rules badLoopingActivity and lonelyActvity).
- You can also try clicking on the warning markers to reveal the offending instance model elements in the abstract syntax editor.
- Finally, you can try how IncQuery validation performs on a larger, real-life BPMN model with some examples found in the bpmn.instancemodel/reallife folder.
Developing validation rules
In order to turn an IncQuery pattern definition into a well-formedness rule, you simply need to add the @Constraint annotation, which takes three parameters:
- location identifies the pattern parameter which should represent a model element that will be the "location" of the violation of the rule. By design of the EMF Validation Marker API, only a single element is allowed to be designated as the location.
- message defines the validation error/warning message that will be shown to the user.
- severity can take either "error" or "warning", giving the developer the possibility to distinguish between these two frequent cases.
The @Constraint annotation will trigger the generation of an auxiliary .validation project which contains some glue code that registers your rule with the IncQuery Validation Engine. The Validation Engine is a generic component that works with the Reflective Ecore model editor, generated EMF tree editors and also GMF-based graphical editors such as the STP BPMN modeler. Additionally, the Query Explorer view is also generic in the sense that it supports the "Show location" feature (by right clicking on matches inside the tree, or double clicking on them) to reveal the instance model elements inside your GMF diagrams automatically.
As the general rule-of-thumb, a meaningful validation pattern should define the "bad case", i.e. match for those cases that represent a violation of the well-formedness constraint. A common technique to specify such patterns is to create a pattern for the "good case", and then use the neg keyword for negation (see lonelyActivity below for an example).
Metamodel pattern matching example: Ecore Queries
Overview
Have you ever tried to query a meta-model, i.e. a model consisting of EClasses, EAttributes, and EReferences, against a meta-model pattern? For an example, look here. In this case, we want to look for a certain sub-configuration in an Ecore metamodel, where two EClasses (each having an EAttribute of type EString) are connected by a 0-* EReference.
Use-cases of this technique include meta-transformation, meta-model analysis, higher-order transformations where transformation rules are generated/parameterized by metamodel analysis etc.
We would like to sincerely thank Christian Schweda for the inspiration for this example.
Obtaining the example
Make sure you run the latest IncQuery tooling and runtime by downloading and installing from the nightly update site.
Check out the source project from GitHub:
Running the example
- Import the ecorequery project into your workspace.
- There is a file in src/hu.bme.mit.incquery.ecorequeries.example directory: queries.eiq, right click on this, select EMF-IncQuery queries | Register patterns in Query Explorer.
- There is a useful, pre-prepared .ecore file in the models/sample directory: My.ecore. Open it, after that click on Load model in Query Explorer View (if you could not see this view then go to Window->Show View->Other->EMF-IncQuery->Query Explorer) .
- You should see the match of the pattern according to the specification found in hu.bme.mit.ecorequery/spec/example.pdf in Query Explorer view.
Sample pattern
The project contains a pattern named SampleQuery. This pattern looks for matches like the picture at the bottom in Ecore Models.
In the first section the pattern filters out two EClasses (XElement,YElement) and the XElement contains a reference to YElement.
The find EReferenceWithStarMultiplicity(Relates); helper pattern filters out references only with star multiplicity.
The find EClassWithEStringAttribute(XElement, Label1); and the find EClassWithEStringAttribute(YElement, Label2); helper pattern filters out EClasses which contains EString.
The neg find IsInECore(XElement); and the neg find IsInECore(YElement); excludes matching to elements located in Ecore.ecore.

Running EMF-IncQuery as an RCP application
Outdated content
The contents of this page have been superseded by the following page on the Eclipse Wiki:
http://wiki.eclipse.org/EMFIncQuery/UserDocumentation/API
Overview
EMF-IncQuery can be used without any graphical user interface (headless). In this example, we take an existing IncQuery project and based on it, we create a (headless) Eclipse Application that can be executed from a console (command prompt) to print the matches for an arbitrary input model file.
First, the IncQuery project headless.incquery can be downloaded from: https://github.com/ujhelyiz/EMF-IncQuery-Examples/tree/master/headless The project contains a single pattern that matches on Ecore models:
Next, observe the application project org.eclipse.viatra2.emf.incquery.application (available at the same place). The project includes two class files:
-
IncQueryApplication: by implementing the IApplication interface, it provides a single entrypoint that is also capable of handling command line parameters. It checks that the input model is provided using the -m <modelPath> switch, the query name provided using the -p <patternFQN> switch and then invokes the pattern matcher.
- To execute the example (on Windows), call as follows (assuming the current folder contains eclipse.exe and the model can be found at c:/test/input.ecore): eclipse.exe -m c:/test/input.ecore - p somePackage.somePattern
- IncQueryHeadless: with a single method execute(String modelPath) that will first try to load the model found at modelPath into an EMF Resource, and if that was successful, it creates a matcher (for the EClassNames pattern) and retrieves the matches as a collection. The actual code also includes some additional fragments to illustrate performance measurements (timed execution for the EMF loading, IncQuery initialization and matchset retrieval phases). Finally, the matches are printed using IPatternMatch.prettyPrint().
Next, the application itself is registered through the org.eclipse.core.runtime.applications extension point. The plugin.xml file defines the extension.
Finally, a product configuration is required in order to run this application as an Eclipse product, and to be able to export it into a standalone application that can be called from the console. Apart from adding the required plugins to the configuration, an org.eclipse.core.runtime.products extension is required as well (also found in plugin.xml):
If only the minimum required plugins are exported, the resulting eclipse folder is around 30 MB, which is quite small considering that an Eclipse Modeling distribution is around 300 MB.
Note that you may have to remove the platform-specific features that are for different platforms (e.g. Linux and MacOS X when using Windows).
Query-driven soft interconnection of EMF models (MODELS12)
We demonstrate how the incremental query evaluation of EMF-IncQuery can be used to maintain soft interconnections between EMF models stored even if they are stored separately, moved or modified without the all the corresponding models loaded at all times.
Overview
The interconnection of complex EMF-based system models imposes several technical problems due to the identification strategies of model elements in the EMF infrastructure. When serializing a model, a model element is either identified by a unique identifier generated by EMF, or by a relative path of containment hierarchy in the given EMF resource. These techniques are used when interconnecting models using associations (EReferences) e.g. for internal traceability purposes: the target end of the association points to an object resided in a different model resource. Such interconnections are also used in external traceability scenarios where inter-model links are introduced from traceability metamodel elements to existing metamodels which cannot be altered.
These scenarios demonstrate various shortcomings of the core EMF technology. First, (1) interconnected EMF model fragments with circular dependencies cannot be serialized. Furthermore, without truly intelligent multi-resource transaction management, (2) local changes in a model fragment may introduce broken links (and consequent runtime exceptions) unless all dependent model fragments are manipulated together in working memory. Such broken links require tool-specific resolutions --- with a worst case scenario of fixing the links manually by the designer using text editors (and not the modeling tool). Finally, (3) all traceability links captured by associations are explicitly persisted every time even if traceability links could be derived from existing unique identifiers.
Query-driven soft interconnections can overcome these challenges and due to the high performance of the EMF-IncQuery engine (see our Performance page), it can be applied in industry tools that handle models with millions of model elements. For example, in AUTOSAR the references between elements are defined in a way that only identifiers are stored and the references are created based on these. Our approach would be an elegant and efficient solution for managing the actual references between the elements using query-driven soft links
For more details on the approach, we suggest that readers to check out the complete paper.
Obtaining the example
- Install EMF-IncQuery as described here.
- Import the derivedModels, derivedModels.edit, derivedModels.editor, derivedTest, derivedTest.validation projects from the attached archive.
- Alternatively, you can check out the projects from https://github.com/ujhelyiz/EMF-IncQuery-Examples/tree/master/query-driven-soft-interconnections (see Generating the EMF-IncQuery code)
Demonstration
Used EMF metamodels
The process metamodel describes simplified business processes including activities (either tasks or gateways).
The system metamodel represents a set of jobs and data objects which are related to the tasks in processes.
The operation metamodel defines checklists which are connected to processes and contain menu and entry elements. Entries refer to tasks in the process of the checklist and jobs in the system model, while they also contain some runtime information as well. The runtime information is also referenced from the job connected to the entry.
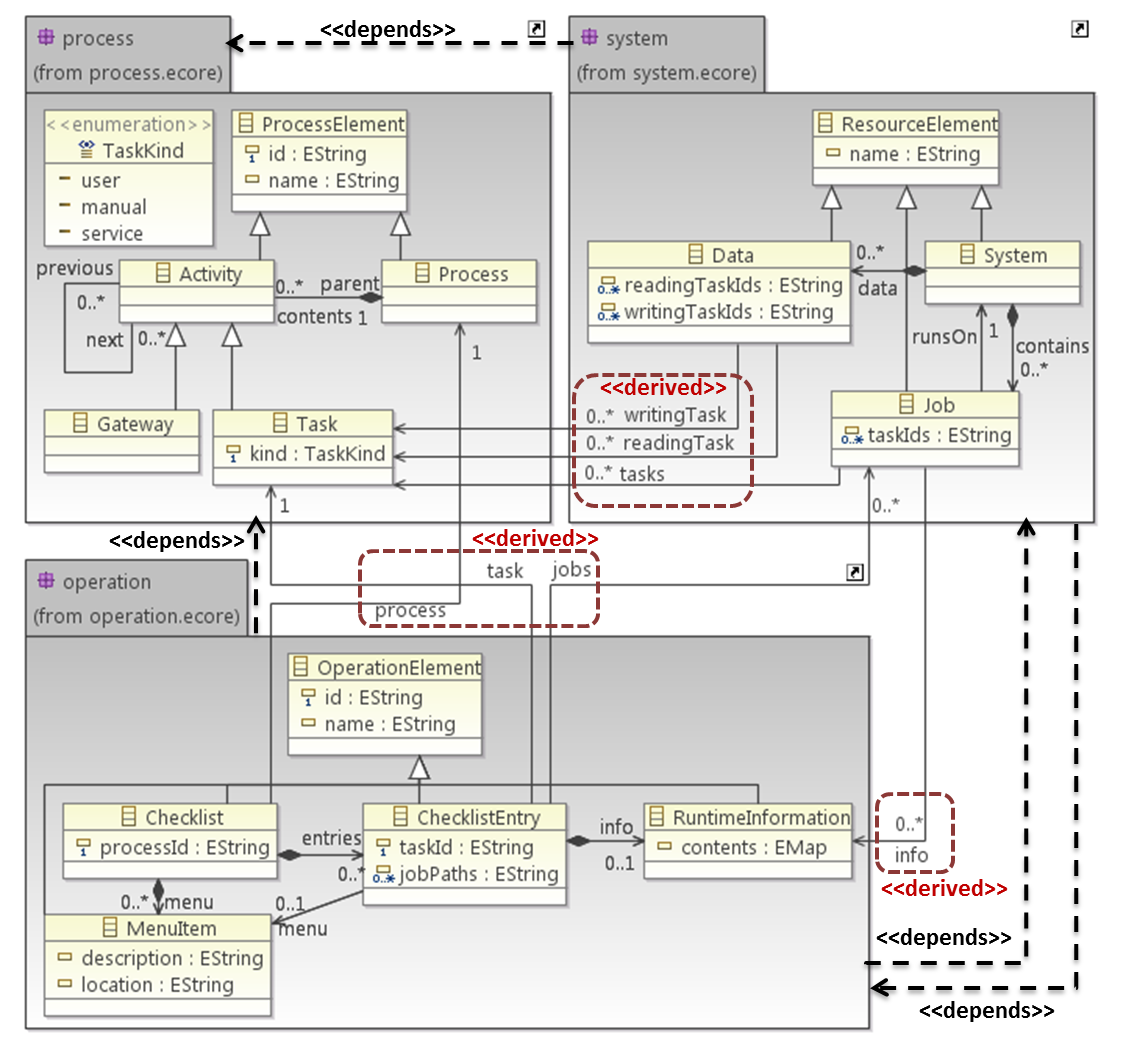
Soft links between the models
- System model
- Job.tasks (refers to the Task in a Process model with the id included in the stored taskIds) and info (refers to an info that is contained by a checklist entry that refers this Job). Note that the definition of the Job.info soft link uses an other soft link (Data.jobs).
- Data.writingTask and readingTask (both refer to Tasks in a Process model with the ids included in the stored taskIds)
- Operation model
- Checklist.process (refers to a process with the id stored in processId)
- ChecklistEntry.task (refers to the Task in a Process model with the id included in the stored taskId) and jobs (since the elements in the System model do not have unique identifiers, the name of the Job and the name of the System that contains it are used as a path)
Loading models including query-based soft links
- Make sure to start a runtime Eclipse with each project included (derivedModels, derivedModels.edit, derivedModels.editor, derivedTest, derivedTest.validation).
- Alternatively, you can install these plugins into the host Eclipse using "Export -> Deployable plugins and fragments -> Install into host".
- Check out the derivedModels.example project from https://github.com/ujhelyiz/EMF-IncQuery-Examples/tree/master/query-driven-soft-interconnections into the workspace. The project contians 4 separate EMF models, which have no direct references to each other. This can be checked by opening one in it's own generated editor, or in the "Sample Reflective Ecore Model Editor". Referenced resources are loaded lazily, so you have to select each element to ensure that no other models are loaded (the models contain less than 10 elements each).
- First, open Simple.system in the "Sample Reflective Ecore Model Editor", navigate to the Job1 or Data elements. Note that the various task ids fields are set, but the tasks fields are not. These derived features will only have a value when the tasks they refer to are loaded.
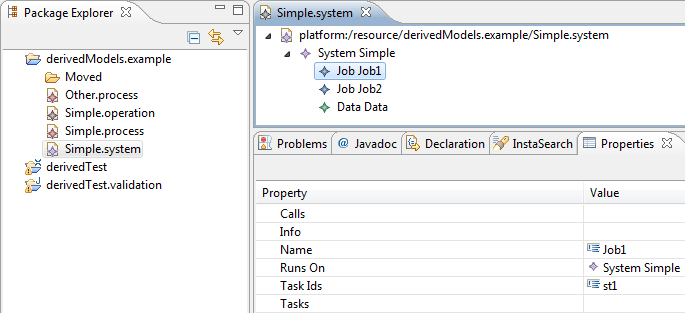
- Next, use the "Load resource" menu, "Browse workspace", and select Simple.process, then press "OK" twice to load the EMF model into the editor. This model contains the tasks corresponding to the ids used by the soft links.
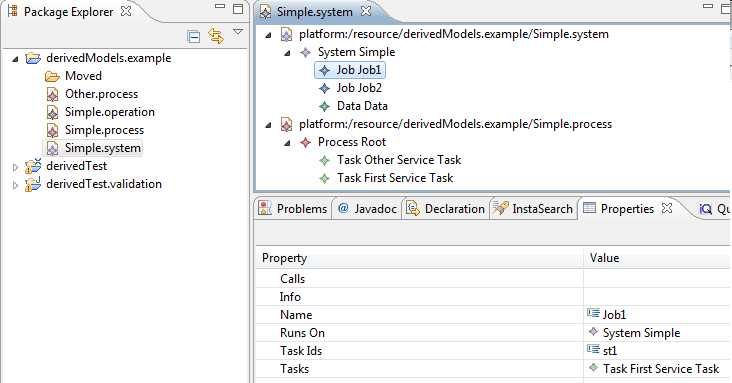
- Similarly, if you load the Simple.operation resource, the Job1.info field will be set, since the loaded operation model contains an entry that references Job1 using the name of the System that contains it and the name of Job1 as a path.
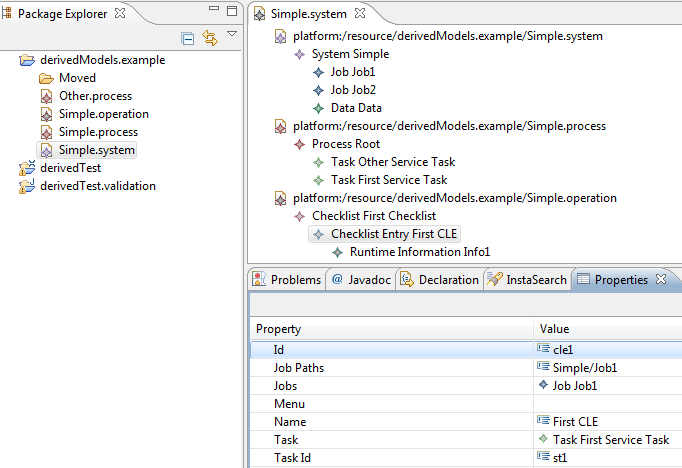
- Note, that you can move the files anywhere in the workspace (even in the file system), it won't break the soft links, since they are backed by queries that are evaluated on the loaded models and use information that doesn't depend on the location of the file. Similarly, you can also rename the files without affecting the soft links.
Validation of soft links
Since the soft-links are computed from attributes that use simple data type values, it is best to have integrated validation that can indicate broken links or links that violate some requirements. For example, the checklist entry refers to a task that is not part of the process that the checklist refers to:
Simply by adding the @Constraint annotation, the relevant source code is automatically generated. You can initialize the validation in the local menu of the "Sample Reflective Ecore Model Editor" (-> EMF-IncQuery -> Initialize EMF-IncQuery validators)
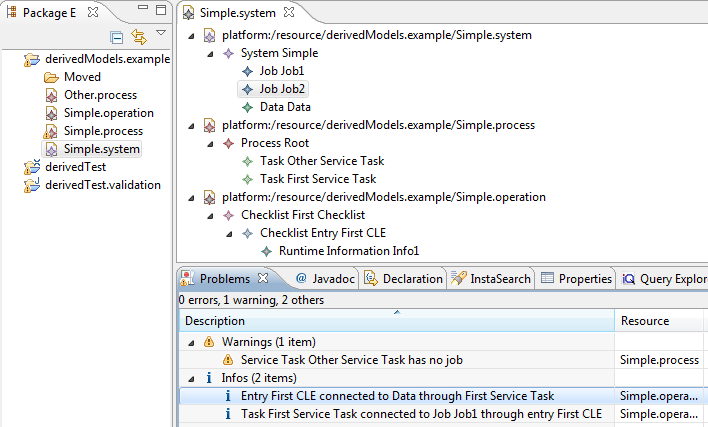
Check out our example for more details on the validation framework.
Developing soft links
Overview of the framework
To support soft links captured as derived features, the outputs of the EMF-IncQuery engine need to be integrated into the EMF model access layer at two points: (1) query results are provided in the getter functions of derived features, and (2) query result deltas are processed to generate EMF Notification objects that are passed through the standard EMF API so that application code can process them transparently.
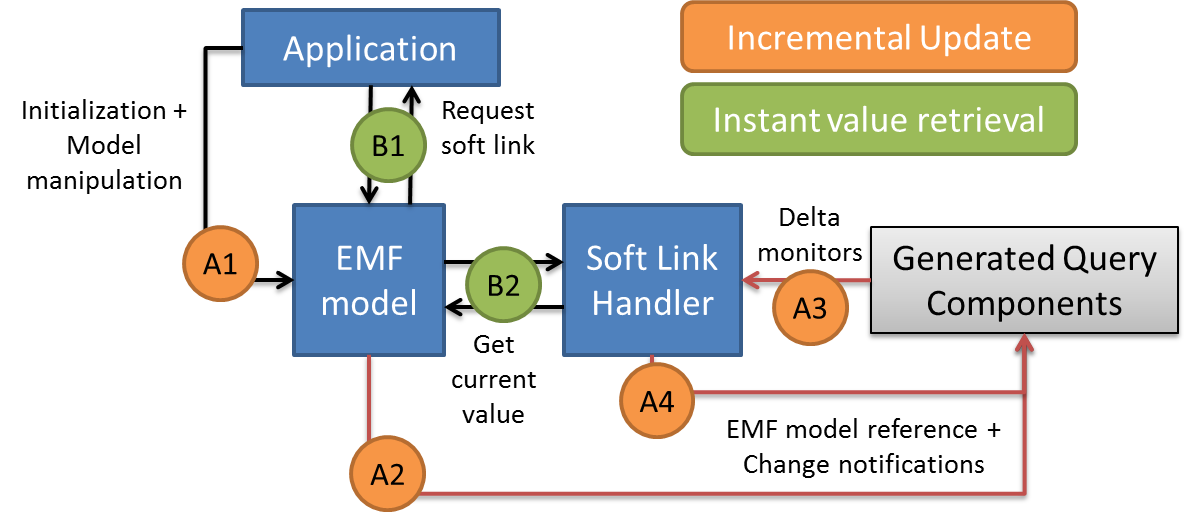
Definition of soft links in the metamodel
First, the soft-links are defined in the metamodels using features with the following configuration:
- derived = true (to indicate that the value of the feature is computed from the model)
- changeable = false (to remove setter methods)
- transient = true (to avoid persisting the value into file)
- volatile = true (to remove the field declaration in the object)
Next, the model code is generated and you can start preparing the query to back the derived feature. For defining derived features using queries, see our derived features example.
Generating the code
- Check out the derivedModels, derivedModels.edit, derivedModels.editor, derivedTest, derivedTest.validation projects from Git into an Eclipse with EMF-IncQuery installed.
- If the src-gen folder in the derivedTest project is empty, invoke the code generation of EMF-IncQuery by selecting Project -> Clean from the menu.
- The glue code for initializing matchers and retrieving values from the handlers are automatically generated based on the @DerivedFeature annotations, as described in the linked example.
Using queries for derived features (ECMFA12)
We demonstrate how our high performance queries can be easily integrated with other EMF tools using an entirely new case study in which EMF-IncQuery is deeply integrated into the EMF modeling infrastructure to facilitate the incremental evaluation of derived EAttributes and EReferences.
Obtaining the example
- Install EMF-IncQuery as described here.
- Get the school-derived, school-derived.edit, school-derived.editor, school-derived-base projects from https://github.com/ujhelyiz/EMF-IncQuery-Examples/tree/master/derived-features-by-queries
Demonstration
- Open Perspective -> Plug-in Development
- Right click / Run As on school-derived-base/School-Derived.launch, select first option (School-Derived)
- In the runtime Eclipse, get school.derived.example from git (same repository and directory)
- Double-click on file My.school to open editor
- Right-click on the School element and select EMF-IncQuery-> Initialize EMF-IncQuery validators action
- Switch to Problems view
- Modify the model using the tree editor to see incremental update in markers
- Add new teachers to school (affects numberOfTeachers)
- Add new year and set startingDate higher than any existing year, also add classes to that year to see changes in the problems view (affects lastYear)
- Modify existing year, either set current last year startingDate lower or increase startingDate on another year (affects lastYear)
- Add courses and set teachers for them, or modify teachers for existing courses (affects teachersWithMostCourses)
Development
In order to integrate IncQuery into your own application, there are three different steps you have to perform. First, you have to indicate that given derived features in your model will be either volatile or provide proper notification themselves in case of changes. Second, you have to create the queries that correspond to the value of the feature. Finally, in case you would like to use derived features in future queries, you must indicate that the use of derived features is allowed in a particular pattern.
Well-behaving derived features
Derived features in general do not ensure that their value is volatile or that they will send notifications upon changes. Therefore, EMF-IncQuery, by default, does not explore the parts of the model which are only reachable through a derived feature, since the incremental query engine would not work properly without correct notifications. However, in some cases the application developer can ensure that a given derived feature will actually adhere to the above limitations (volatile or notification facility). In EMF-IncQuery, we call these features "well-behaving", since they behave correctly in regards to the query engine.
Well-behaving features can be registered through an extension point (org.eclipse.viatra2.emf.incquery.base.wellbehaving.derived.features), where the package namespace URI, the name of the classifier containing the feature and the name of the feature must be given. These extensions are read when the EMF-IncQuery runtime plug-in is loaded for the first time.
Example:
Implementing well-behaving features in Java
Existing applications that already make use of derived features most likely has some kind of implementation. In EMF applications, the value of a derived features is usually calculated from the value of local features of the given classifier or features of classifiers accessible through navigation from the classifier. Therefore, it is possible to define (during design) the set of dependant features that the value of a given derived feature depends on. These features are either non-derived features (and well-behaving by definition) or well-behaving by implementation, thus they will send notifications about changes.
In order to ensure that a derived feature is well-behaving, the notifications of dependant features must be listened to and proper change notifications must be sent when the value of the given derived feature changes due to a change in the value of a dependant feature. Implementing such behavior for each derived feature independently would require a huge effort, thus we decided to implement an enhanced version of the derived attribute notifier found here.
EMF-IncQuery now contains a Derived Feature Handler that can be used in any EMF application for registering dependant features for any derived feature. It provides a few convenience methods for adding dependant features and sends notifications about changes on the value of the derived feature. These methods can be used for adding local and navigated features to a handler for a given derived feature.
For example, if the teachersWithMostCourses, lastYear and numberOfTeachures features from the above example are used, registering can be done in the following way in the constructor of the classifier:
new DerivedFeatureAdapter(this, SchoolPackage.Literals.SCHOOL__NUMBER_OF_TEACHERS, SchoolPackage.Literals.SCHOOL__TEACHERS);
The number of teachers derived attribute only depends on the teacher local feature of School.
new DerivedFeatureAdapter(this, SchoolPackage.Literals.SCHOOL__LAST_YEAR, SchoolPackage.Literals.SCHOOL__YEARS, SchoolPackage.Literals.YEAR__STARTING_DATE);
The last year depends on the starting date attribute of the years of the given School.
new DerivedFeatureAdapter(this, SchoolPackage.Literals.SCHOOL__TEACHERS_WITH_MOST_COURSES, SchoolPackage.Literals.SCHOOL__TEACHERS, SchoolPackage.Literals.TEACHER__COURSES);
The teachers with the most courses are calculated from the courses feature of the teachers in a given school.
IncQuery based derived features
Queries that are intended for use as derived features are developed in the same way as regular EMF-IncQuery queries. The only difference is that some of the generated code should be in the same project with the model code. Once the pattern builders, matchers and signatures are generated for the features, the glueing code is generated into the EMF model code directly.
Example queries, the derived features will be numberOfTeachers, teacherWithMostCourses and lastYear:
The @DerivedFeature annotation tells the code generator to handle the given pattern as a derived feature definition.
The generated code will look similar to the following:
First, at the first getter call of the derived feature, a derived feature handler is created with proper parameters:
The IncqueryFeatureHandler.getIncqueryDerivedFeature is a convenience method for instantiating and starting a feature handler. The first parameter is the source object, the second is the EStructuralFeature, the third is the pattern fully-qualified name usable for initializing the matcher for the appropriate query. The fourth parameter identifies which parameter of the signature is the given object, while the fifth identifies the target of the feature in the query signature. The sixth parameter defines what kind of derived feature value is required, counter kind will track the number of matches for the query, single and multi reference kinds define whether a single target or a list of targets are possible. The last two boolean parameters specify whether a cache is kept for the value and whether the query is matched in the containment subtree under the source or the whole resourceset (or resource if the resourceSet is not available).
The last thing to do is to implement the getter functions of the derived features. The IncQuery derived feature created previously has a getValue method that returns the current value of the given feature. In order to provide more type-safe ways of accessing the current value, there are three other methods: getIntValue() that returns the value of counter kind features, getSingleReference() returns a single object, while getManyReference returns a collection of objects. Note that in the case of many reference, the getter usually returns an EList, which should be instantiated in the getter as an unmodifiable list, this is already done with the getManyReferenceAsEList method.
Realtime gesture recognition with Jnect and Esper
Overview
- the Jnect plugin for processing Kinect Data
- the Eclipse Modeling Framework as the underlying live model representation format
- EMF-IncQuery for realtime pattern matching to recognize static gestures
- the Esper complex event processor to recognize gesture sequences in the event stream generated by IncQuery.
The overall goal is to demonstrate that the combination of these technologies yields a system that is capable of recognizing gestures (both static states and dynamic sequences) in a (soft) realtime fashion with common, off-the-shelf hardware.
We are aware that gesture recognition can be implemented in many different (more efficient) ways, however the aim is to highlight the fact that Eclipse technologies and EMF(-IncQuery) in particular can be embedded into high performance applications, while retaining the well-known benefits of the model-driven/model-assisted approach.
Acknowledgements
We wish to thank István Dávid for help with Esper and Dr. Jonas Helming for providing the original idea for the "YMCA" demo.
Presentation
The following video illustrates the system in action as it was presented at EclipseCon Europe 2012:
The Jnect-IncQuery Realtime Complex Gesture Recognition Demo presented at ECE2012 from istvan Rath on Vimeo.
The following slideshow contains a high-level overview of the architecture:
Trying the demo
Getting the code
The complete source code for this demo is available under open source licences at Github.
Please note that several modifications were required to the original Jnect source to make this work, so the Github repository contains all necessary sources for running the software - the original Jnect should not be present in your configuration.
Additional videos
YMCA
This video demonstrates the system in action. A test user performs the complete "YMCA" gesture sequence, where each character is represented by a particular body configuration as depicted here:
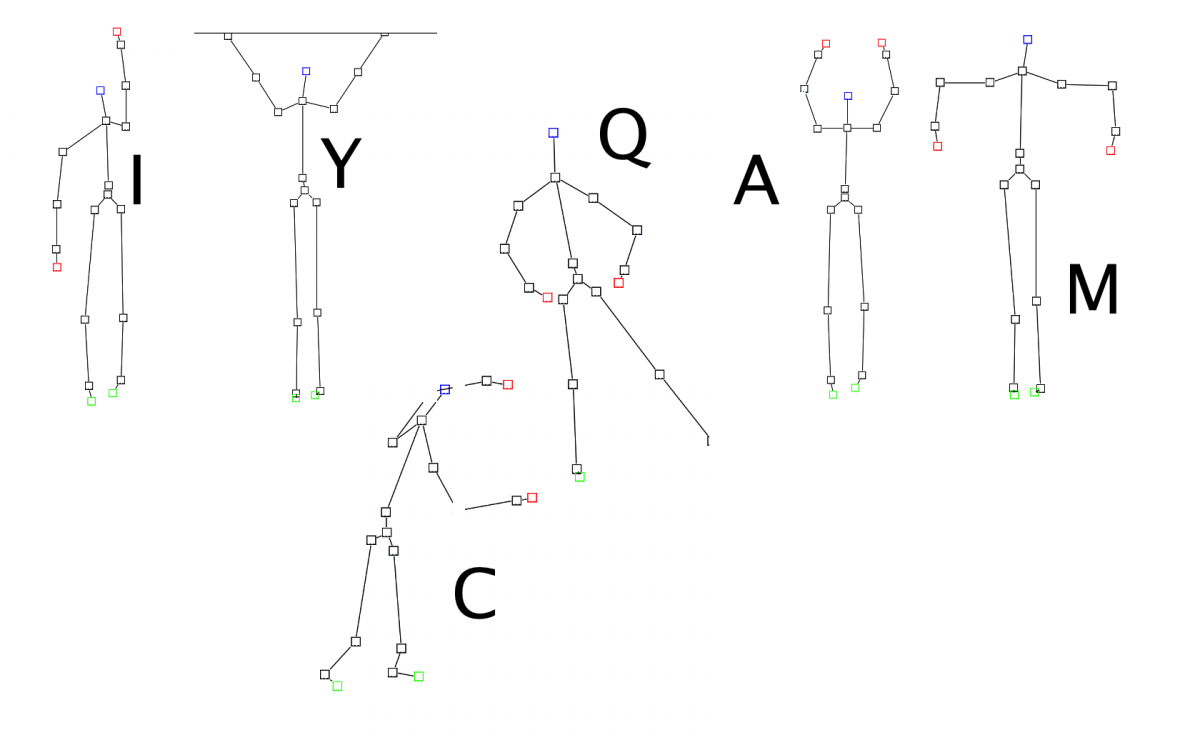
Each character is recognized as a graph pattern match on the live body model, and converted into an " atomic recognition event". (Shown as e.g. "[Y]" in the upper text field.) The Esper CEP engine continuously analyzes the event stream (managing time windows while doing so) and whenever the complete "YMCA" (or "IQ") sequence is recognized the "[ YMCA ]" character sequence is displayed.
The Robot Demo
This video demonstrates two features:
- a gesture sequence (consisting of the "straight arm" as a starting state and the "bent arm" as the end state) is defined based on graph patterns and complex event patterns
- this gesture sequence is then translated to operating system-level keypresses so that an external tool (Powerpoint) can be controlled.
How it works
The basis for this demo is the live EMF model maintained by the Jnect plugin. Essentially, Jnect converts the XML stream coming from the Microsoft Kinect SDK into an EMF instance model. In each "frame", the XML document contents are copied into the EMF model - these informations mostly contain coordinates of body parts. Approximately 20 such frames are processed per second.
Realtime pattern matching by EMF-IncQuery
Jnect's live EMF model is processed by EMF-IncQuery. EMF-IncQuery is an incremental query engine that instantiates complex graph-pattern based queries over EMF instance models, and automatically processes the model's changes (using the EMF Notification API) so that the query results are always kept up-to-date.
The "Y" pattern demonstrates an example for such a query. EMF-IncQuery queries are best read as a high-level, declarative specification (consisting of a set of constraints) that need to be fulfilled by the model. Those model parts that fulfil the constraints of the query make up the match set.
In this example, the "match set" of the Y query will consist of a tuple defined by the RH, RE, RS, LH, LE, LS, H variables that will be bound to the EObjects corresponding to the user's body parts. The Y pattern is fulfilled if the body of the user reaches a state where all sub-queries (constraints) of the Y pattern hold.
The "upperArmsInY" pattern may be of particular interest. This pattern is used to define a geometrical constraint on the upper arms of the user. EMF-IncQuery allows the developer to include Xbase expressions (that will be compiled to Java code) and here this feature is heavily used to wire vector math calculations into the query.
Complex event detection by Esper
EMF-IncQuery not only keeps the result/match set of queries up-to-date all the time, but it also provides event-driven deltas through its DeltaMonitor API that allows the developer to process changes in the query results in an efficient, event-driven way.
Feeding IncQuery pattern match events into Esper's event stream
This code snippet demonstrates how the DeltaMonitor API can be used. In each turn (the callbackAfterUpdates callback Runnable is called ONLY if there is a change in the result set of the query -- that is, the body state has changed enough so that gestures need to be updated), the .matchFoundEvents and .matchLostEvents collections are processed and each newly found match is converted into a PatternMatchEvent DTO that will be pushed into the Event stream.
Recognizing IncQuery pattern match events in discrete time windows
The Esper complex event processor is then used to process the stream of such events.
The AtomicPatternFilter demonstrates a basic EPL query that picks out a single ("distinct") atomic pattern match event from a 1 second time window, and then
EventPatternListener provides feedback into the Esper event stream, turning the isolated low-level PatternMatchEvent into an EsperMatchEvent.
Recognizing complex event patterns
Finally, complex event filters such as YMCAFilterWithWindowFeedback are used to search the stream of higher level EsperMatchEvents for complete gesture sequences like "YMCA".
EMFxcel: Having Fun with Excel and Eclipse Modeling Tools
In order to be able to do advanced data processing and visualization with technologies I am familiar with, I created a simple tool to process Microsoft Excel® documents using Eclipse Modeling Framework. The solution consists of an Xcore-based Excel domain, and a slightly modified EMF generated editor that is able to open Excel files directly as EMF instance models via Apache POI, and automatically track and propagate changes as the opened file is being simultaneously modified in Excel. I demonstrate live data processing using EMF-IncQuery graph queries, and live data visualization using IncQuery Viewers.
The source code and sample models that belong to this example is found at https://github.com/ujhelyiz/EMF-IncQuery-Examples/tree/master/emfxcel, and it requires the brand new EMF-IncQuery 0.8 release that can be downloaded from the Eclipse Marketplace (among others).
The problem
In my experience, next to traditional programmer tools such as IDEs and compilers, Microsoft Excel® is one of the most frequently used software development programs. This is because even today, many organizations tend to keep documentation, requirements, and other auxiliary data related to software development processes in Microsoft Office documents, and particularly Excel spreadsheets. Managers love spreadsheets, right? :-)
So, many of us need to work with Excel documents, and sometimes this goes beyond just opening these files and looking at their contents. What if, say, you need to process the contents programmatically, in order to perform (non-trivial) calculations or extract data to feed into some other program? The obvious solution, one might think, is to use Excel's built-in facilities such as macros.
Here is a simple example problem that I had to solve the other day (I modified the contents and schema to simplify things quite a bit). We have a document that consists of multiple worksheets, each of which contains several rows and columns — in our example, students and courses. We want to check if there are any students who applied to multiple courses, and if there are any who applied to none.
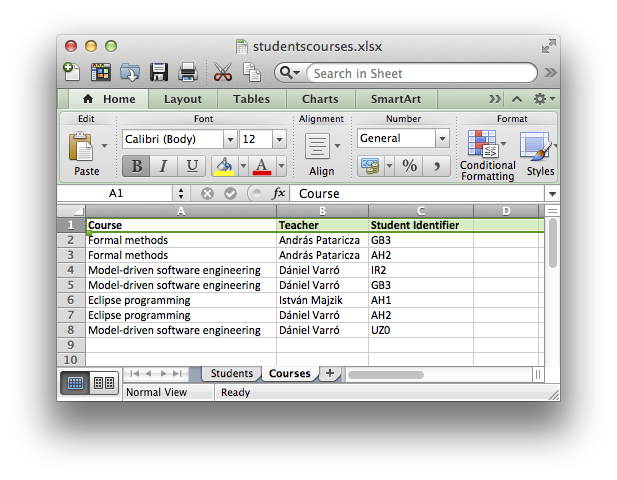
So, what if you are like me, and don't want to learn advanced Excel magic just to be able to do a few such tricks using Excel data? Furthermore, what if you are already familiar with Eclipse Modeling? Isn't there a way to map Excel into an EMF model and use your favourite Eclipse Modeling technologies such as EMF-IncQuery and Xtend to do the processing? Now there is.
The solution
I was initially sure that this is such a common problem that somebody must have already come up with something. It turned out not to be the case, so I rolled my own and it proved to be a very smooth and pleasant experience. Read on below.
Modeling Excel in Xcore
The first step is to create a simple domain model to represent Microsoft Excel documents as EMF instance models. I used the excellent Xcore framework to draft such an Ecore domain model in an easy-to-use textual syntax. See below for the code.
My approach was to build something simple but already powerful and easily extensible. The basic building blocks (Workbook, Worksheet, Row and Cell) are motivated by the concepts of the Apache POI library and I added a bit of redundancy (namely, explicit indices in Cell elements) to make data processing easier later on. Data types are handled by subtypes of Cell such as BooleanCell, StringCell and NumericCell. These few subtypes were enough for my purposes, but other can be easily added if necessary.
Generating the EMF Editor
The next step is to generate an EMF model editor, in order to be able to test drive our domain model. (I know, this could be done using dynamic instances, but I prefer generated editors.) So I added the @Ecore and @GenModel annotations to my Xcore file (see above) so that the necessary code is generated. Once that is done, I ran the generated editor as an Eclipse Application and created some example models similar to the one below.
Overriding the Editor
The final touch was to make sure that the editor can open actual Excel documents and instantiate my domain model with their contents. As stated before, I integrated the Apache POI library and wrote some simple code to do the transformation from POI objects to the corresponding EObject counterparts. See the populateResource() funtion below for details.
My editor contains a further enhancement: it registers a listener on the workspace, so that whenever the opened file is changed from the outside (e.g. by Excel), this change is picked up and the contents of the EMF instance model are repopulated with new data. This will be important later on. See the registerResourceChangeListener() function below for details.
Once these things were done, I was able to open actual .xlsx files with my editor and see their contents. Now on to the fun part.
Model Queries with EMF-IncQuery
Okay, let's do some live data processing on our Excel documents. To solve my problem, I wrote a couple of EMF-IncQuery queries. If you are not familiar with the syntax of the language or how the IncQuery development tools work, I suggest to read the IncQuery Wiki, and check out some other, more detailed examples.
Here, I am making full use of a new IncQuery 0.8 feature called "Query Libraries", which allows to reuse queries defined in a different file (which may be in a different project or bundle, as long as it is available on the classpath of my IncQuery project). So first, I wrote some generic queries that will be helpful to more concisely and simply code queries specific to my problem. See the code below.
In this query library shown in the snippet above, I wrote three helper queries:
- CellInWorksheet(C: Cell, WorkSheetName, RowNum, ColNum) is useful to identify individual cells by a worksheet name (that you can see on the Excel UI), and the respective row and column indices (all integers starting from 0).
- NamedColumn(WorkSheetName, ColName, ColNum) is useful to identify a column index as a "named" column, i.e. when the 0th row contains the string substituted for ColName.
- valueInNamedColumn(wsName, colName, rowNum, value) is useful to "extract" a cell value from a worksheet and named column, indexed by row number (rowNum).
My problem-specific queries demonstrate the usage of the last one (the first two are actually only used internally). See below.
Here, I am now writing domain-specific queries using the generic queries defined in my query library above.
- student(name, id), teacher(name) and enrolledStudent(courseName, teacherName, studentId) are helper queries that aid in identifying important concepts.
- didNotApplyForAnyCourse(name) and appliedToMultipleCourses(name) are the queries that finally solve the original problem.
The screenshot below illustrates what I see after loading both the query definitions and my example instance model into the Query Explorer using the green play button.
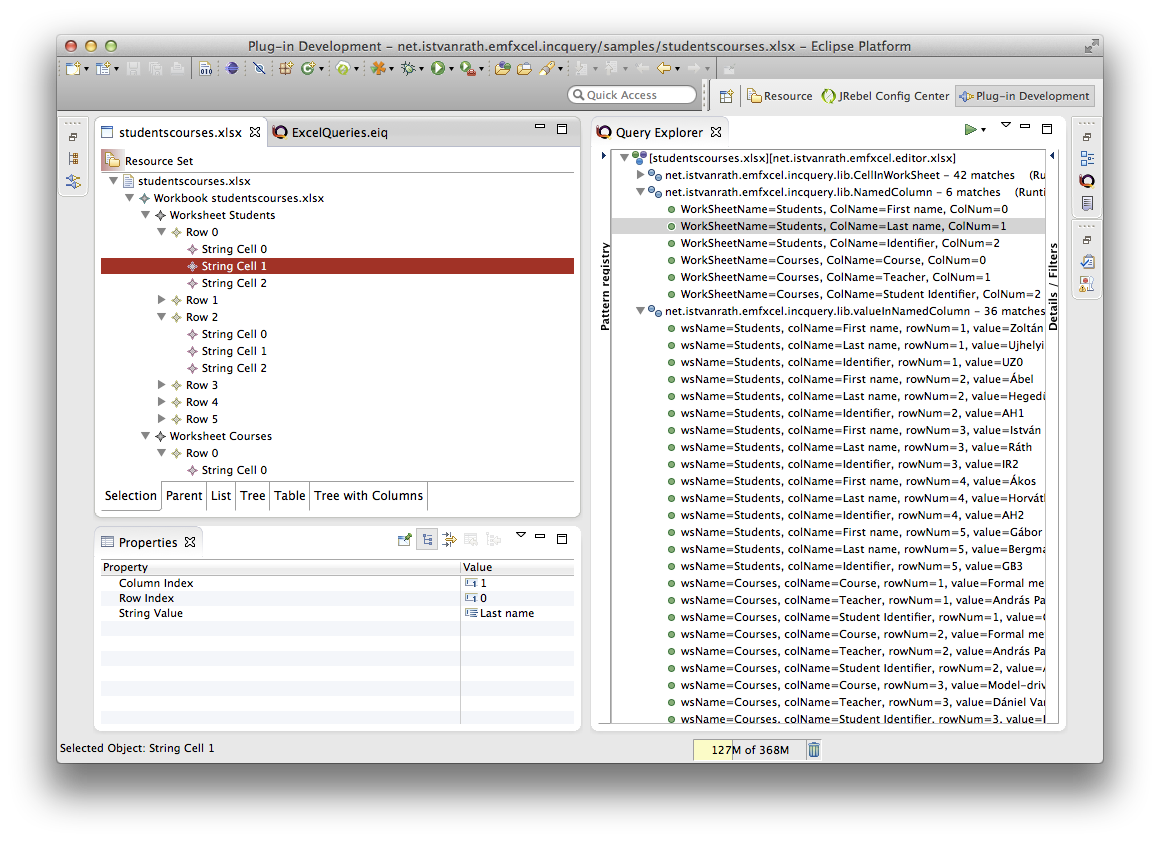
Visualization with IncQuery Viewers
IncQuery Viewers is an add-on to EMF-IncQuery that is intended to support powerful and automatic data visualization using standard Eclipse UI technologies such as JFace and Zest. The basic idea is that using Viewers, query results can be automatically mapped to UI contents such as list/tree entries or graph nodes and edges. It is important to note that this is live visualization, which means that whenever the underlying model changes, the query results are incrementally recomputed by EMF-IncQuery, and these changes are also incrementally propagated to the UI through Viewers.
To showcase the powerful visualization capabilities of IncQuery Viewers, I added a couple of annotations to my domain-specific queries above.
- @Item annotations are used to make students and teachers appear as items (list/tree entries and graph nodes),
- @Edge annotations are used to make relationships computed as query match results appear as graph edges.
The screenshot below demonstrates how the results are automatically rendered by IncQuery Viewers as a 2D graph powered by the Zest framework. The IncQuery Viewers Sandbox view is triggered automatically by right clicking on the queries in the central section of the Query Explorer, and selecting "Reinitialize IncQuery Viewers" from the menu.
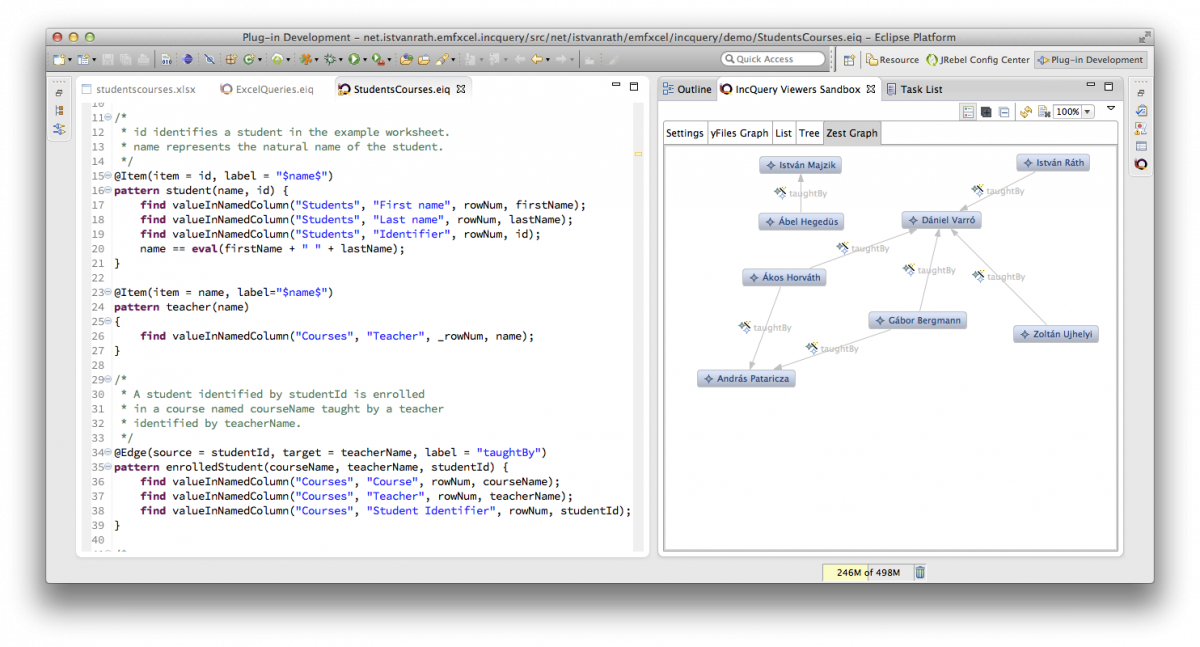
Tracking Changes Automatically
OK, on to the final touches: we want to make sure that whenever we edit the document in Excel, the changes are propagated into the Eclipse tool so that query results and visualization contents are automatically updated. We turn on native hooks in order to make Eclipse automatically react to external file changes (since Excel will be running outside of Eclipse, of course). The setting is found under Preferences.
Let's see how this works. The screenshot below shows my Excel documents at the staring point.
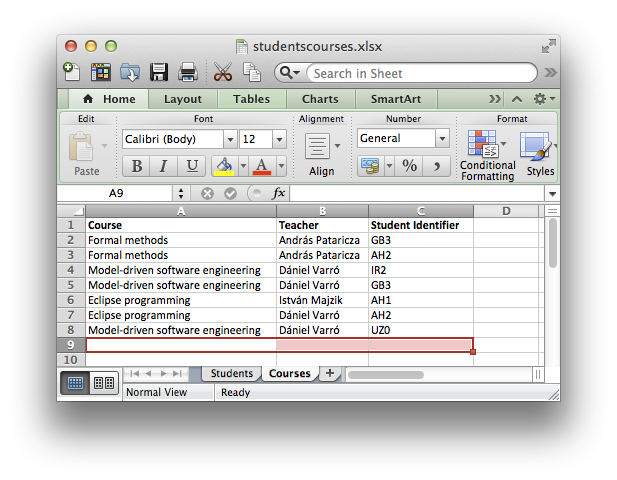
This is what I see in my Eclipse tool:
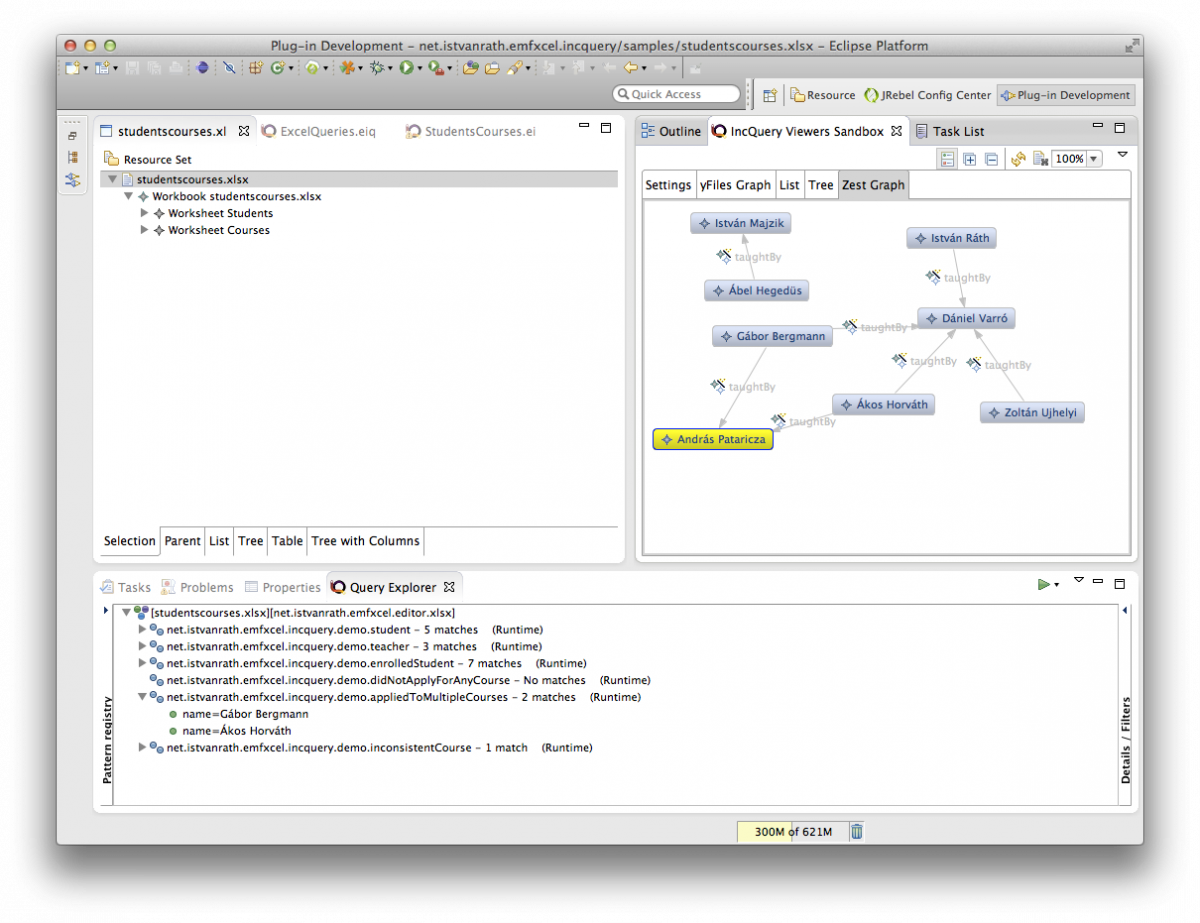
Now let's assume I do some editing in my Excel document (I add a new row to the Courses worksheet), and then push save:
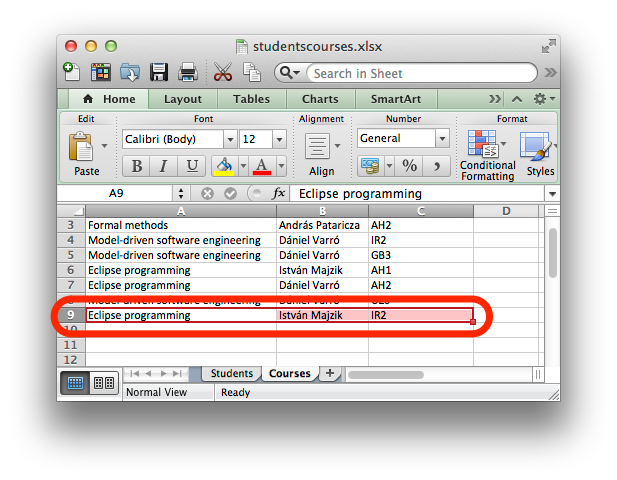
After a few milliseconds, the changes are automatically propagated into Eclipse, and the contents of the Query Explorer and the IncQuery Viewers Sandbox are updated according to my changes.
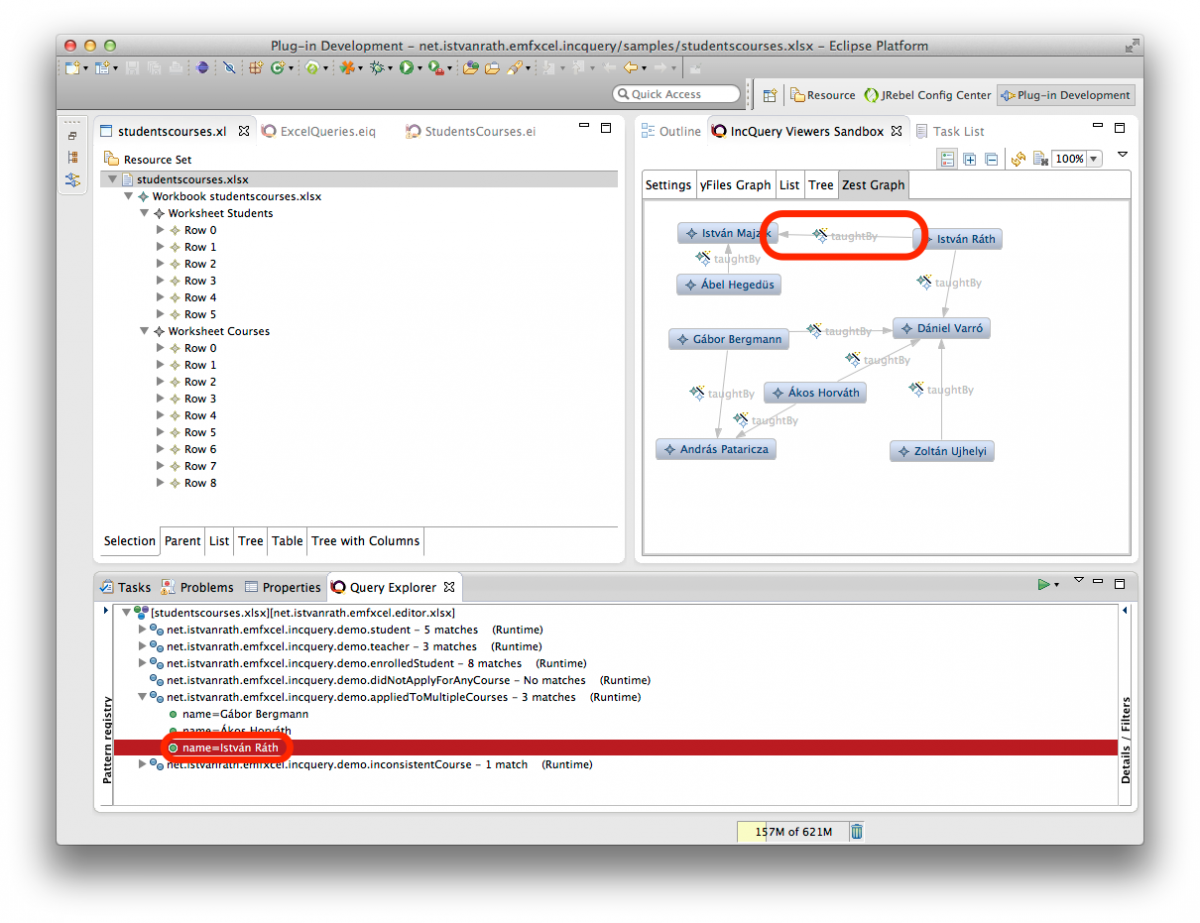
That's it!
Frequently Asked Questions
This content is outdated and completely superseded by https://wiki.eclipse.org/EMFIncQuery/FAQ#Common_issues
Q: What does EMF-IncQuery call the 'qualified name' of a graph pattern?
It is actually the fully qualified name, which is the qualified name of the containing package, a separator dot, and the simple name in the pattern (the one you define it with after the pattern keyword). The qualified name of the package has dot-separated segments, like in Java.
Q: What does EMF-IncQuery call the 'qualified name' of a graph pattern?
It is actually the fully qualified name, which is the qualified name of the containing package, a separator dot, and the simple name in the pattern (the one you define it with after the pattern keyword). The qualified name of the package has dot-separated segments, like in Java.
Q: What is the complexity of pattern matching?
In our typical use cases, as patterns are relatively small, and their constraints are pretty restrictive, therefore the size of the match set does not grow combinatorically, as predicted by the theoretical worst case scenario.
The total memory usage (of the EMF application plus IncQuery) will be the size of the model + the size of the match set, and actually slightly more than that because some intermediate results are also cached and incrementally maintained. As of now, we do not carry out any deep query optimization, so in some corner cases these "intermediate results" can grow much bigger than the match set - although usually they don't. A good advice here is to look for small, connected parts of patterns that occur more than once, and refactor them into a separate helper pattern that will be called from all the original occurrences using the 'find' keyword. We have summarized best practices on how to avoid problems on the performance page.
Query evaluation time is pretty much instantaneous. Actually at low level, the result set has has to be copied, but then usually you will want to iterate over it anyways, so this won't be the dominant cost. Note that getOneMatch() can be much faster than getAllMatches(). If you have some bound input parameters (as opposed to retrieving all matches globally), then the restricted result set is even smaller, and is accessed with a cheap hash-based lookup.
Update time (i.e. model manipulation overhead) is related to how many new matches appear or old ones disappear due to the modification, and also the amount of change in the internal caches and indices. Most typically, a single change in the model only makes a very limited amount of change in the match set and the internal caches, and is therefore cheap.
Initialization time is composed of reading the model and then filling up the caches and indices accordingly. The latter one is basically the update overhead on model element creation times the size of the model, as the mechanism is almost the same as the one that will maintain the cache afterwards upon model updates. As for model reading, the current version (see below) traverses the entire model once, when the first matcher is constructed for the given pattern and EMF model. Depending on pattern contents, a re-traversal may be required for newly registered patterns -- this behavior will change in the near future for a more flexible approach, whereby the developer will be able to identify batches of patterns that should be initialized together (see also the next question).
For further information, see our performance page.
Q: How and when are the match set caches initialized?
You can attach a pattern matcher engine on an EMF model root (preferably EMF ResourceSet or Resource, but potentially any containment subtree) at any time (that is, even before any contents have been loaded). In the current version, at most one pattern matcher engine is built for each of these EMF "roots" (this is true per IncQueryEngine; you can create separate "unmanaged" engines that will not share pattern matcher caches with the default "managed" engine). It is constructed when you first initialize a pattern matcher on that root, and the next time you instantiate a pattern matcher (for the same or a different pattern) on the same root, it will reuse the underlying engine. However, if the second pattern uses model features (e.g. element types) that were irrelevant for the first pattern, then the engine must re-traverse the model to gather additional information.
With optimum performance in mind, you need to consider the followings:
- If you initialize several patterns using various model elements on a (large) model that has already been loaded, there could be many repeated "model read" traversals over the entire ResourceSet (depending on the contents of the patterns). In exchange, memory is allocated by IncQuery only gradually, as you initialize the matchers step-by-step.
- In order to avoid the model (re)traversal for initialization, another option is to initialize all IncQuery matchers your application will use on a Resource(Set) before its contents have been loaded. This way, no additional initialization overhead is experienced due to pattern matcher initialization operations, however all memory is allocated at once.
- Alternatively in wildcard mode, the IncQuery engine will cache all EObject and reference types during the first model traversal, which means that independently of the contents your patterns, no further retraversal will be necessary. This mode is on by default for development time, with an option to opt-out in case you need to work with large models. If you want to use wildcard mode during runtime, refer to the API Javadoc.
- IncQuery can now handle groups (batches) of patterns together: a new API feature allows to initliaze a (freely defined) group of patters together in one go, without needlessly traversing the model several times. The development environment will treat patterns residing in the same .eiq file as a group. During runtime, you can compose a PatternGroup however you will, with built-in support for the group of registered (generated) patterns declared within a single package. The code generator also generates a group from each .eiq source file.
Q: Does IncQuery need to load all the models into memory, or only the necessary ones like EMF Model Query 2?
IncQuery was primarily designed to define and execute queries against models that are already in the memory. If you initialize a "matcher" on a ResourceSet that has already been filled with the contents of the model, as addressed in the previous question, IncQuery will perform an exhaustive model traversal, and while doing so, it will trigger the loading of any referenced external resources. If the model is changed at a later time to refer to additional external resources, they will be loaded into the ResourceSet as well.
In the development environment, the Query Explorer initializes the pattern matchers for the entire ResourceSet (used by the host editor from which the model is being used). In order to better support working with fragmented models, we support a feature whereby the developer has ability to restrict the matcher initialization to only the main Resource of host editor by selecting an alternative action for the green button of the Query Explorer. (Note that API even support setting the matcher scope to the containment subtree below any EObject.)
In summary, IncQuery does not currently concern itself with querying "workspace" models (i.e. models that are not loaded into memory inside some editor, for instance). In this sense, it is complementary to Model Query 2. However, Model Query 2 could be extended to use IncQuery-based model indexers, to speed things up considerably. This is a feature that we plan to implement sometime in the future.
Q: What is included in the query results if the matcher is attached to an EMF model root that is not the entire ResourceSet, just some Resource or containment subtree?
Every EObject in the containment subtree below the selected EMF model root will be considered for pattern matching, as well as their attributes and the EReferences interconnecting between them. EReferences pointing outward from the subtree, as well as the elements they are directly pointing to, currently may or may not be considered (depending on complicated things), so do not assume either case. Nothing else will be considered.
Q: What is included in the query results if the scope of the matcher is the entire ResourceSet?
You do not have to worry about any of the above if the scope is given as the entire ResourceSet - in this case, all EObjects and their attributes and references will be considered, regardless in which Resource of the Set they reside in. If the initially loaded Resources contain references to external Resources, they too will be resolved and loaded within the ResourceSet.
However, there are a few other exceptions discussed in the next point.
Q: What else is included in the query results? Why do I see the contents of some external EPackages, such as Ecore?
If the EMF model root is a ResourceSet, the scope of query evaluation will also include external resources that are refererred from the ResourceSet but not attached to any ResourceSet. (This does not happen normally, as ResourceSets are typically closed w.r.t. references.) A frequent occurrence of this phenomenon is nsURI-based references to metamodel elements in registered EPackages - e.g. from .ecore models. This is why you might see referenced EPackages appearing in the results, when you run queries against an .ecore model. In fact, you might see some duplicate EPackages as well, if there are nsURI-based and "platform:"-prefixed references alongside each other - which is the correct result, as these will be separate objects.
Q: How does one use attributes?
Use the EAttributes as path expressions in the pattern definition to navigate from the EObject to its attribute value. Let's say the constraint House.owner.name(ThisHouse, OwnerName); binds the variable OwnerName is now bound to an attribute value (of type java.lang.String, more precisely EString). Afterwards, the raw value can be directly used in a check() condition, or in any other pattern constraint, or even as a parameter variable. The equality of two attribute values can be asserted by a '==' constraint between the two variables, such as MyAge == YourAge; or even by using the same variable in both path expressions. For inequality, the operator '!=' is provided; for more complex attribute checks, use a check() expression.
See the EMF-IncQuery language tutorial and the School example for details.
Q: How are null-valued features represented in the query language?
Unset or null-valued attributes (or references) simply won't match, as there is no referenced EObject or attribute value to substitute in the target pattern variable. If you are especially looking for these, use a negative application condition (neg find hasXYZ(...)).
Q: How does the generic pattern matcher API work (as opposed to the generated ones)?
There is a "generic" matcher with a corresponding generic match class; they are not as easy to use as the pattern-specific generated classes, but they conform to the same reflective interfaces. You can get an instance of merely by providing the Pattern object directly. See GenericPatternMatcher in the API Javadoc.
Q: What are MatcherFactory classes for?
MatcherFactory classes can create the associated (generated / generic) Matchers with some type-safe Java generics magic. This might be useful in a trigger engine or other very generic system, as you can collect a large number of matcher factories that contain all knowledge about the pattern, and parametrize them later to specify the actual EMF model to match against. Using Java generics, you can have a method that handles match objects in a type-safe way for each matcher created from the collection of factories.
Instead of calling the constructor of a generated Matcher, you can also use its static factory() instead to attach a matcher to an EMF model. There is also a GenericMatcherFactory for the generic matcher. You can use the MatcherFactoryRegistry to obtain a matcher factory for a Pattern.
Q: What is the delta monitor, and how to use it?
It is a device that can be attached to the pattern matcher. From that time on, it will keep track of newly appeared matches, as well as previously existing but disappeared ones. So by default it monitors the difference between the current state and the time it was created. You can remove these matches from the delta monitor yourself to 'acknowledge' them; for that particular match, the difference (appearance / disappearance) from that time on will be displayed instead.
See the source code of the EMF-IncQuery validation framework for example usage.
Q: Can patterns be defined recursively?
Theory: the language does not forbid the usage of recursive patterns, however great care should be taken when using this feature. If the recursion is not well-founded, i.e. matches can circularly support each other, then the result may be different from what you expect (technically, the matcher does not observe minimal fixpoint semantics, the fixpoint it stabilizes upon may be non-minimal).
Practice: most of the time, people want to write recursive patterns to evaluate some kind of transitive closure. If you can, just use the built-in transitive closure operator (find myPattern+(A,B)), and then you have nothing to worry about. If your use case is too complex, you can experiment with recursive patterns on your own risk; if the model graph itself is DAG (acyclic) w.r.t to the edges that your pattern traverses, you should be fine.
EMF-IncQuery Base Documentation
About IncQuery Base
EMF-IncQuery Base aims to provide several useful (some would even argue critical) features for querying EMF models:
- inverse navigation along EReferences
- finding all model elements by attribute value/type (i.e. inverse navigation along EAttributes)
- computing transitive reachability along given reference types (i.e. transitive closure of an EMF model)
- getting all the (direct) instances of a given EClass
The point of IncQuery Base is to provide all of these in an incremental way, which means that once the query evaluator is attached to an EMF model, as long as it stays attached, the query results can be retrieved instantly (as the query result cache is automatically updated). IncQuery Base is a lightweight, small Java library that can be integrated easily to any EMF-based tool.
We are aware that some of the functionality can be found in some Ecore utility classes (for example ECrossReferenceAdapter). These standard implementations are non-incremental, and are thus do not scale well in scenarios where high query evaluation performance is necessary (such as e.g. on-the-fly well-formedness validation or live view maintenance). IncQuery Base has an additional important feature that is not present elsewhere: it contains very efficient implementations of transitive closure that can be used e.g. to maintain reachability regions incrementally, in very large EMF instance models.
Incremental algorithms
The library contains incremental algorithms. In the case of EMF models, an incremental algorithm will visit the whole model only once (when the algorithm is initialized on the model) and after that it will maintain the data structures based on the modifications in the model, without visiting the whole model again. For the transitive closure this will result a remarkable performance speedup; because of the incremental manner of the algorithm, only small portions of a large-scale model will be visited when a modification occurs. Nevertheless, this comes with a price: for large EMF models the incremental algorithms will use additional memory, because the data structures are kept in memory during runtime. The implementation of the algorithms allow to dispose them (and the data structures) any time during the life-cycle.
Getting started
Example metamodel
In the tutorial we will use a simple EMF model which consists of the following elements:
- Library: a library which contains books and writers
- Writer: this element represents a writer who has books in the library
- Book: this element represents a book instance. A book can reference another books via citations.
- Manuscript: this element is a subclass of the Book. It has an additional state attribute which indicates the level of preparedness in percent.
Note that this metamodel is a slight modification of the metamodel which is used in many EMF tutorials (http://www.eclipse.org/edapt/libraryexample.php).
The following figure is the Ecore Diagram of the metamodel.
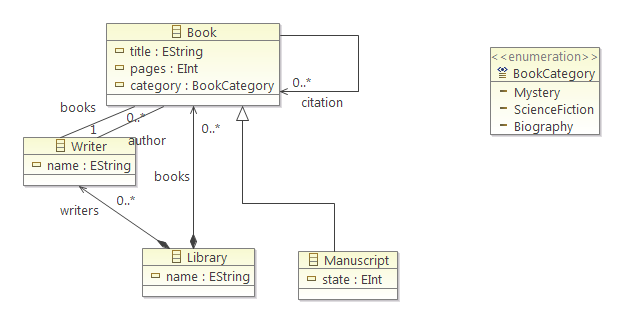
Project setup
You can download the required projects from the github repository of EMF-IncQuery:
- EMF-IncQuery Base from https://github.com/ujhelyiz/EMF-IncQuery.
- The example from https://github.com/ujhelyiz/EMF-IncQuery-Examples/tree/master/library.
You will need the following plug-ins:
- org.eclipse.viatra2.emf.incquery.base: the base plug-in which provides the functionalities mentioned above.
- org.eclipse.viatra2.emf.incquery.base.itc: this plug-in contains several static and incremental transitive closure algorithm's implementation.
- org.eclipse.viatra2.emf.incquery.base.test: this plug-in will be used for the demonstration of the project as it contains all the code that will manipulate a test EMF model and execute the queries. It registers an editor contribution too for the Library Editor.
Follow these steps to run the project:
- You will find a library.genmodel file under the model folder in the org.eclipse.viatra2.emf.incquery.base.test project. Open it and from the context menu choose Generate Model, Edit and Editor Code. This will create 3 plug-ins, named org.eclipse.viatra2.emf.incquery.base.test.library, org.eclipse.viatra2.emf.incquery.base.test.library.edit and org.eclipse.viatra2.emf.incquery.base.test.library.editor.
- Create a new Eclipse Application Run Configuration: go to Run menu -> Run Configurations. Choose Eclipse Application and add a new one.
- Optionally rename the Run Configuration as you like.
- Go to the Plug-ins tab and select Launch with -> plug-ins selected below only.
- Select all the six projects mentioned in this tutorial: the 3 downloaded and the 3 generated in the first step.
- Click on the Add Required Plug-ins button, this will select all the required plug-ins
- Click Apply and then Run. This will start a new Eclipse instance (Runtime Eclipse).
The test project
- Import the Test project in the Runtime Eclipse, the project can be found in the attached zip archive.
- The project contains a model folder and a lib.library instance model in it.
- Open the model with the Library Editor.
- Explore the instance model, you will find a Library instance in it and under the Library there can be found several Writers and Books, Manuscripts.
- You will find a button 'Execute EMF-IncQueryBase queries' in the menu above the editor. Please note that this is a simple, demonstration example so this button only works with the sample model in the test project.
Simple queries
You will find several example queries in the org.eclipse.viatra2.emf.incquery.base.test plug-in's TestModule1.java file (executeQueries method). Note that, the example will print the match results to the STANDARD OUTPUT.
-
Query 1 Find all EObjects in the model which have an attribute with the value 100.
-
Query 2 Find all Books in the model whose 'pages' attribute's value is 100.
-
Query 3 Find all instances of the Book EClass. This will return the Manuscripts too, since Manuscript is a subclass of Book.
-
Query 4 Find the proper instances of the Book only, no Manuscripts.
-
Query 5 Find all references pointing to the Da Vinci Code book. This will result in the Library instance, Dan Brown Writer and the book Alchemist which cites Da Vinci Code.
-
Query 6 Find all Library instances having Da Vinci Code in their 'books' reference list.
-
Query 7 Find the inverse references of the Da Vinci Code book but only along the 'books' reference of Library and the 'citation' reference of Book.
Transitive Closure queries (query 8)
We will demonstrate the usage of the TransitiveClosureHelper with the books and their citations in the library.
Suppose we want to borrow a book from the library but we also need all the books which is referred from the selected book via citations, because those may be necessary to understand the selected one (the required books may refer another books which also should be borrowed). This results that we have to know the transitive closure of the graph where the nodes will be the books and each reference between two books will be represented with an edge. To borrow the required books we have to query all the reachable targets of the selected book.
However, if we often go to the library we may query the "target" books many times which will result that we need an algorithm to compute it quickly. In this scenario an incremental algorithm will be really useful which will maintain the required books' citations automatically.
For example if we want to borrow the Angels and Demons book then we don't need to borrow any other books because it is an isolated node in the graph. However, if we want to borrow the Da Vinci Code we will need the Digital Fortress Manuscript, the Faithful Place, Alchemist and the 11 minutes Books too (query 9). Note that Da Vinci Code itself is also present in the result set as the engine allows self-loops.
The following figures illustrates the process of computing the result for the reachable targets of Da Vinci Code.
EMF-IncQuery Base Programmer documentation
IncQueryBaseFactory - integration with EMF models
The library provides the following interfaces:
- NavigationHelper: defines methods to query inverse navigation along EReferences and EAttributes and instances of a EClasses.
- TransitiveClosureHelper: defines methods to query the transitive closure of a given EMF instance model.
Use the IncQueryBaseFactory class to create an instance implementing one of the above mentioned interfaces. You must pass a Notifier instance which is the root of the your EMF model. Only the sub model under the given EObject/Resource/ResourceSet root will be visited by the helper instances.
Note that if you do not need an instance later on, call the dispose method of the given interface to properly dispose the data structures of the given algorithm.
NavigationHelper
The NavigationHelper interface exposes the following methods (JavaDoc):
https://build.inf.mit.bme.hu/jenkins/job/EMF-IncQuery-Javadoc/javadoc/or...
The Helper can be instantiated either in wildcard mode or in 'parameterized' mode. In wildcard mode, every aspect of the EMF model is automatically indexed. In 'parameterized mode', however, only selected types of model elements and features are indexed. Unused indices take up memory, so turn off wildcard mode to decrease the memory usage while working with very large models.
Unless in wildcard mode, the client has to register EClasses, EDataTypes and EStructuralFeatures before the Helper can index them and find../get... methods can provide the appropriate results. Note that registering new types will cause the Helper to re-iterate through the entire model to expand its index, which is costly, so it is best to register everything you need at once.
TransitiveClosureHelper
The TransitiveClosureHelper interface exposes methods to query reachability information along given EReferences in the EMF model. You must pass a Notifier instance and a set of EReferences when creating a helper instance with the appropriate method of the IncQueryBaseFactory class. The set of EReferences represents those instances which will be treated as edges in the 'graph'.
The TransitiveClosureHelper interface extends the ITcDataSource<V> interface defined in the org.eclipse.viatra2.emf.incquery.base.itc project. In this case the type parameter will be the EObject interface.
The ITcDataSource interface exposes the following methods (JavaDoc):
https://build.inf.mit.bme.hu/jenkins/job/EMF-IncQuery-Javadoc/javadoc/or...
New and Noteworthy
Version 0.6.10
Fixed the validation of emf models with wrapper objects in them (EBooleanObject, EIntegerObject, etc). Apart from that some minor bugfixes and extensions are also added.
For all fixed issues, see https://github.com/ujhelyiz/EMF-IncQuery/issues?milestone=11&state=closed
Version 0.6.9
Various minor bugfixes regarding mostly the validations and the QueryExplorer.
For all fixed issues, see https://github.com/ujhelyiz/EMF-IncQuery/issues?milestone=9&state=closed
Version 0.6.8
A single new feature is added: a validator for cartesian product-styled patterns. These patterns use a larger amount of memory and provide potentially unwanted matches, so it is not recommended to define such patterns.
Version 0.6.7
Bugfix release, fixing some issues related to
- the databinding framework
- Transitive closure support
Version 0.6.6 has a major issue that has been quickly fixed for 0.6.7. If you have downloaded version 0.6.6, please update to the newer version.
For all fixed issues, see https://github.com/ujhelyiz/EMF-IncQuery/issues?milestone=8&page=1&state...
Version 0.6.5
The main highlights of version 0.6.5 are the followings:
- Since the last officially publicized milestone (0.4), more than 30 man-months of development effort have been invested into the project.
- The new version features a significantly rewritten pattern matching engine using IncQuery Base. IncQuery's pattern matcher, as in previous versions, is capable of nearly instantaneous query (re)evaluation performance for very complex queries over large instance models up to several million EObjects in size. Version 0.6.5 improves on 0.4's core capabilities by including support for efficient transitive closures.
- EMF-IncQuery now has a state-of-the-art Xtext-based Eclipse UI.
- Interpretative query evaluation (originally appearing in 0.6.0) enables the query developers to test their queries without generating code from them first. Of course, the generated version performs better (due to compiled check expressions) and has an easier-to-use, pattern-specific generated API.
- In addition to the powerful graph-pattern based query language, IncQuery also has experimental support for Xbase check expressions so that you can include (side effect free) imperative logic and even Java code into your queries.
- The query language features automated variable type inference and several other validation rules to make the development of complex, structured queries easier and faster.
- Notable additional top-level features include:
- Support for query-backed derived features and soft links (as presented at MODELS 2012)
- A rewritten Validation Engine that provides high-performance on-the-fly evaluation for complex model validation rules.
- We have also put a lot of work into the website, most notably:
- The documentation section has been extended to cover all important aspects of the technology, including the User Interface, the Query Language, and the Java API.
- The continuously maintained and expanded Examples section provides starting points and hints for new as well as experienced users.
For the list of all fixed issues see https://github.com/ujhelyiz/EMF-IncQuery/issues?milestone=7&page=2&state...
Migrating to version 0.7.0
API changes
Databinding plug-in
-
The
ObservablePatternMatchListclass has been extended with a generic type parameter. Additonally, a new factory method is availabe (similar to other databinding factories). See the classIncQueryObservablesfor details.
Query-based Features
- All corresponding code has been moved to a separate plugin.
- The handler, helper and corresponding classes have been renamed. This should not cause problems if you regenerate your code.
- The annotation is changed to @QueryBasedFeature, the old annotation is marked as deprecated.
Architecture changes
New component: incquery.triggerengine plug-in
- validation.runtime and databinding.runtime now depends on this new plug-in
Renamed all projects
| Old name | New name | Remarks |
| org.eclipse.viatra2.emf.incquery.databinding.runtime | ||
| org.eclipse.viatra2.emf.incquery.tooling.generator.databinding | ||
| org.eclipse.viatra2.patternlanguage.emf | ||
| org.eclipse.viatra2.patternlanguage.emf.ui | ||
| org.eclipse.viatra2.patternlanguage.generator.util | ||
| org.eclipse.viatra2.patternlanguage.core | ||
| org.eclipse.viatra2.patternlanguage.core.ui | ||
| org.eclipse.viatra2.emf.incquery.derived | ||
| org.eclipse.viatra2.emf.incquery.tooling.generator.derived | ||
| org.eclipse.viatra2.emf.incquery.base.itc | ||
| org.eclipse.viatra2.emf.incquery.base | ||
|
org.eclipse.viatra2.emf.incquery.runtime.gmf org.eclipse.viatra2.emf.incquery.validation.runtime.ui.gmf |
Restructured GMF specific code | |
| org.eclipse.viatra2.emf.incquery.runtime.graphiti | ||
| org.eclipse.viatra2.gtasm.patternmatcher.incremental.rete | Version number downgrade to 0.7.0 | |
| org.eclipse.viatra2.emf.incquery.runtime | ||
|
org.eclipse.viatra2.emf.incquery.tooling.core org.eclipse.viatra2.emf.incquery.tooling.generator |
Merging two projects | |
| org.eclipse.viatra2.emf.incquery.tooling.generator.model.ui | ||
| org.eclipse.viatra2.emf.incquery.tooling.generator.model | ||
| org.eclipse.viatra2.emf.incquery.tooling.generator.ui | ||
| org.eclipse.viatra2.emf.incquery.tooling.retevis | ||
| org.eclipse.viatra2.emf.incquery.tooling.gui | ||
| org.eclipse.viatra2.emf.incquery.validation.runtime.ui | ||
| org.eclipse.viatra2.emf.incquery.validation.runtime | ||
| org.eclipse.viatra2.emf.incquery.tooling.generator.validation |
Changes to Generated Code
As the generated code of EMF-IncQuery depends on the EMF-IncQuery runtime, the renaming of the projects cause the generated projects not working. However, we made sure that all the pattern definitions should work in the new release as well. There are two ways to update the existing EMF-IncQuery project:
- Create a new EMF-IncQuery project using the project wizard, and copy the eiq and eiqgen files and possibly any other manually written file to the new project. Matcher (and integration) code is regenerated, and the project will be ready to use.
-
Manually update the existing project:
-
Open the .project file of the project, and update the nature and builder references. An example for the rewriting is available in the following GitHub Gist
- Old version:
- New version:
- Remove all references of generated code from the plugin.xml.
- Trigger a full rebuild of the project to regenerate all matcher and integration code.
-
Open the .project file of the project, and update the nature and builder references. An example for the rewriting is available in the following GitHub Gist