Benchmarking query technologies in EMF based model-validation scenarios
Model Driven Development systems exploit the benefit of instance model validation and model transformation. Ever-growing model sizes used for example in critical embedded systems development require more and more efficient tools. The most time consuming step during model validation or model transformation is the model query step. This benchmark aims to measure batch style query and incremental style query performance of existing EMF based tools.
Authors: Benedek Izsó, Zoltán Szatmári, István Ráth, Ákos Horváth, Gábor Bergmann and Dániel Varró
This benchmark page was created to supplement the article: EMF-IncQuery: An Integrated Development Environment for Live Model Queries
For extended preliminary performance benchmark results see this page.
Case Study Overview
The benchmark uses a domain-specific model of a railway system that contains most typical class diagram constructs. This metamodel will be instantiated, and concepts of the metamodel can be used in queries.
Metamodel
The metamodel is defined as an EMF metamodel:
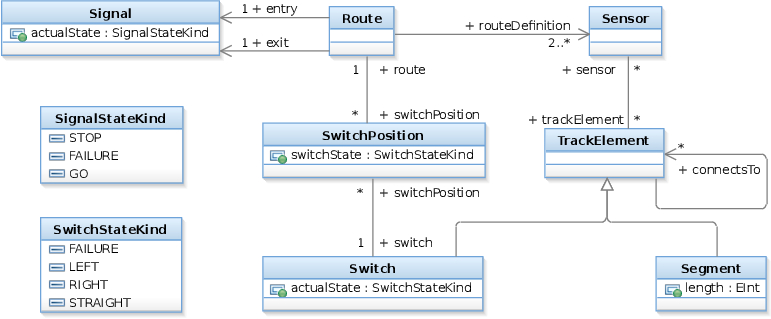
A train route can be defined by a set of sensors between two neighboring signals. The state of a signal can be stop (when it is red), go (when it is green) or failure. Sensors are associated with track elements, which can be a track segment or a switch. The status of a switch can be left, right, straight or failure. A route can have associated switch positions, which describe the required state of a switch belonging to the route. Different route definitions can specify different states for a specific switch.
Constraints
Several high-level requirements can be specified that must hold for any valid instance models of a train system. The queries of the following constraints must return constraint violating elements.
Requirement 1
| Name | SwitchSensor |
| Textual description | Every switch must have at least one sensor connected to it. |
| Graphical graph pattern | 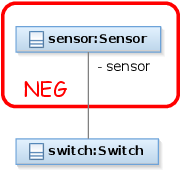 |
| Graph pattern |
pattern switchSensor(Individual) = { pattern hasSensor(Trackelement) = { |
| OCL query |
context Switch: |
Requirement 2
| Name | PosLength |
| Textual description | A segment must have positive length. |
| Graphical graph pattern | 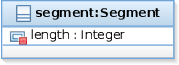 |
| Graph Pattern | pattern posLength(Source, Target) = { Segment(Source); Segment.Segment_length(Source, Target); check((Target as Integer) <= 0); } |
| OCL query |
context Segment: |
Requirement 3
| Name | RouteSensor |
| Textual description | All sensors that are associated with a switch that belongs to a route must also be associated directly with the same route. |
| Graphical graph pattern | 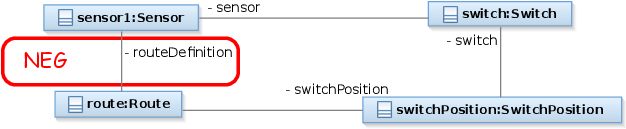 |
| Graph pattern | pattern routeSensor(Sen, Sw, Sp, R) = { Route(R); SwitchPosition(Sp); Switch(Sw); Sensor(Sen); Route.Route_switchPosition(R, Sp); SwitchPosition.SwitchPosition_switch(Sp, Sw); Trackelement.TrackElement_sensor(Sw, Sen); neg find head(Sen, R); } pattern head(Sen, R) = { |
| OCL query |
context Sensor: |
Requirement 4
| Name | SignalNeighbor |
| Textual description | A route is incorrect, if it has a signal, and a sensor connected to another sensor by two track element, but there is no other route that connects the same signal and the other sensor. This pattern checks for the absence of cycles, so the efficiency of join is tested. One-way navigable references are also present in the constraint, so the efficient evaluation of these are also tested. |
| Graphical graph pattern | 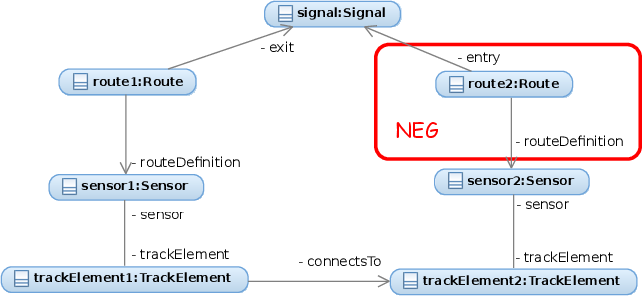 |
| Graph pattern | pattern signalNeighbor(R1) = { find exitSignalSensor(SigA, R1, Sen1A); find connectingSensors(Sen1A, Sen2A); find rDefinition(R3A, Sen2A); R3A != R1; neg find entrySignalSensor(SigA, _R2A, Sen2A); } pattern exitSignalSensor(Sig, R1, Sen1) = { find exitSignal(R1, Sig); find rDefinition(R1, Sen1); } pattern entrySignalSensor(Sig, R2, Sen2) = { find entrySignal(R2, Sig); find rDefinition(R2, Sen2); } pattern entrySignal(R, Sig) = { Route(R); Signal(Sig); Route.Route_entry(R, Sig); } pattern exitSignal(R, Sig) = |
| OCL query | context Route: oclIsKindOf(Route) and self.Route_exit->exists(signal | self.Route_routeDefinition.Sensor_trackElement.TrackElement_connectsTo.TrackElement_sensor->exists(sen2 | Route.allInstances()->exists(route2X | (route2X <> self) and route2X.Route_routeDefinition->includes(sen2) ) and not ( Route.allInstances()->exists(route2 | route2.Route_routeDefinition->includes(sen2) and route2.Route_entry = signal ) ) ) ) |
Instance model generation
The model generator instantiates the metamodel and generates EMF instance models, with size ranging from a few thousand elements (nodes and edges) up to approx. 14*109. The generator randomly introduced faulty element configurations into the model (with low percent). The distribution of nodes belonging to a type and outgoing degree of typed edges are depicted in the following diagram:
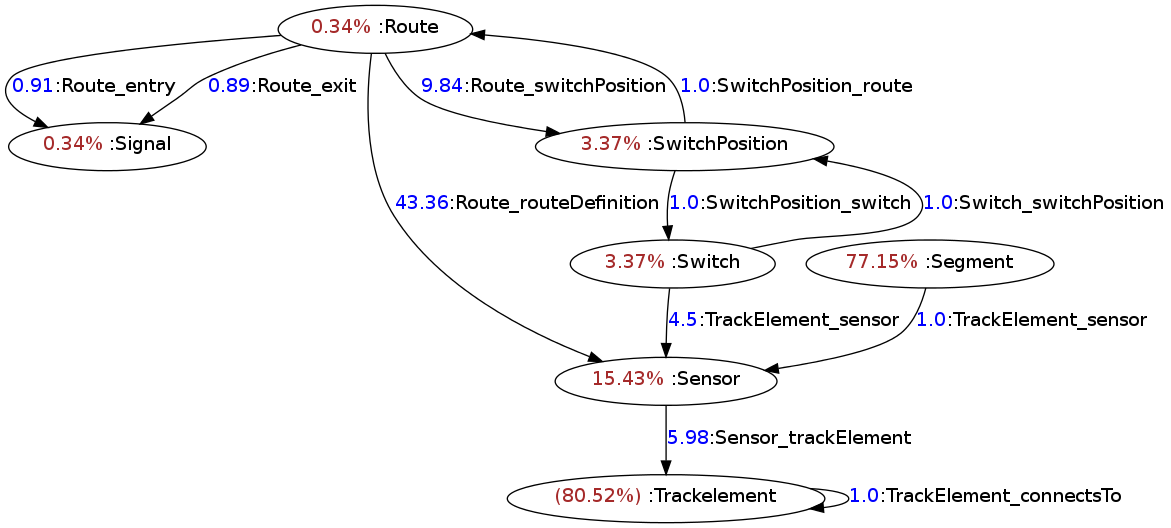
Benchmark description
The benchmark simulates a typical model validation scenario in a model-driven system development process where small and local modifications are applied to large models (i.e. the knowledge base changes), and well-formedness constraints are continuously re-evaluated to check the correctness of the result model and highlight design flaws for engineers. A benchmark scenario is built up from well defined phases.
Phases:
- Read: In the first phase, the previously generated instance model is loaded from hard drive to memory. This includes parsing of the input, as well as initializing data structures of the tool. The latter can consume minimal time for a tool that performs only local search, but for incremental tools indexes or in-memory caches are initialized.
- Check, re-check: In the check phases the instance model is queried for invalid elements. This can be as simple as reading the results from cache, or the model can be traversed based on some index. Theoretically, cache or index building can be deferred from the read phase to the check phase, but it depends on the actual tool implementation. To the end of this phase, erroneous objects must be available in a list.
- Modify: In the first part of this phase, elements to be modified are selected. This is not measured, since it involves tool-dependent queries, and query performance is measured in the check phase in a more systematic way. The time of the second part is recorded, which consists only of instance model edit operations, like modifying objects, or deleting relations.
During the benchmark, the time of each phase is measured using nanotime precision which does not mean nanotime accuracy, this is why the highest resolution is 1 ms in the presented diagrams.
Scenario:
In the scenario defined by the benchmark a developer is assumed to sit in front of a model editor. The user first reads the model from file. Next a check is performed, reporting low number of constraint violating elements (0.06% of model elements for the RouteSensor case), so it can be understood and resolved by a human using the editor. During the modification the user always performs 100 random edits (fixed low constant) which increases the number of erroneous elements. These edits modifies only some elements of the model, and does not add or remove modules containing multiple instance model elements. Every edit is immediatelly followed by a re-check.
Technical details
Measurement environment
The exact versions of the used software tools and parameters of the measurement hardware are shown in the following list.
- Measured tools
- EMF-IncQuery 0.7.1.20130704131
- Eclipse OCL 3.3.0.v20130610-1317
- OCL Impact Analysis 3.2.100.v20130520-1527
- Environment
- Eclipse: Kepler
- Java version 1.6
- Ubuntu precise 64 bit
- Hardware
- CPU: Intel(R) Xeon(R) CPU L5420 @2.50 GHz
- 32 GB RAM
Measurement procedure
The benchmark procedure is implemented as Java applications (or Eclipse Application where necessary). The binaries are independent (i.e.: jar-s are not included which are not dependencies), and the tests are executed in different JVMs in a fully automated way.
To reproduce our measurement please follow these steps:
- Setup the 64 bit Linux environment with Java and Eclipse Kepler
- Checkout the metamodel project into an Eclipse workspace from SVN:
- In a runtime Eclipse (where the metamodel plug-in is loaded) checkout the benchmark projects from SVN:
- hu.bme.mit.Train.common
- hu.bme.mit.Train.constraintCheck
- hu.bme.mit.Train.constraintCheck.eoclia
- hu.bme.mit.Train.constraintCheck.incQuery.0.6
- hu.bme.mit.Train.constraintCheck.incQuery.0.6.patterns
- hu.bme.mit.Train.constraintCheck.mdtocl
- Checkout the instance model project holder from SVN:
- In the RuntimeConstants.java file of the hu.bme.mit.Train.common project set workspacePath to point to the workspace containing the hu.bme.mit.Train.InstanceModel project.
- Instance models can be generated automatically with the generator, but it is easier (and recommended) to simply download the previously generated EMFinstance models. After unzipping, there must be a file named e.g.: hu.bme.mit.Train.InstanceModels/models/testBig_XForm_1.concept.
- Testcases must be exported to runnable JAR files (Eclipse OCL and the Impact Analyser) or as Eclipse products (for EMF-IncQuery).
- The whole benchmark can be run utomatically with the help of scripts in hu.bme.mit.Train.tests.nativ . (scripts/runTestsSep.sh for the runnable JARs and runTestsSep.Prod.sh for Eclipse Applications.)
Measurement results
As the exact tasks done by a tool (independently from the actual API calls) can happen in one phase or in another, two wall clock times were measured, which hopefully results in a more fair comparison:
- Batch validation: is the sum of the read and first check phase.
- Incremental validation: is the sum of all edits and re-checks (checks excluding the first one).
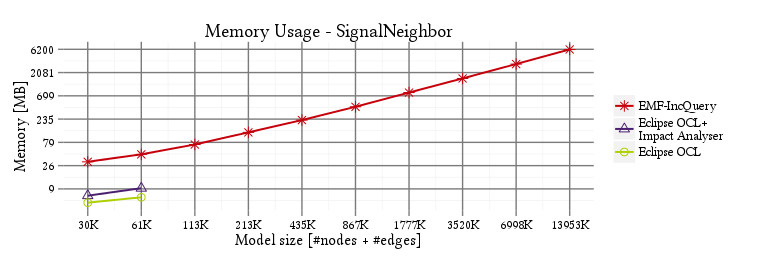
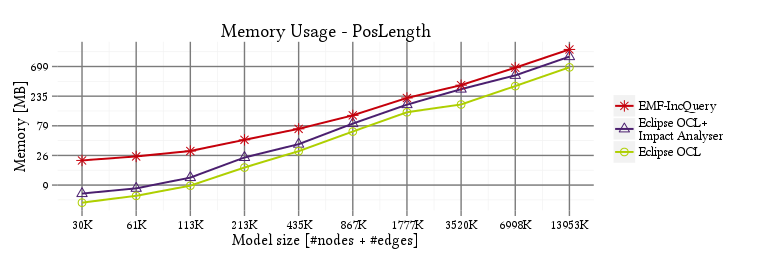
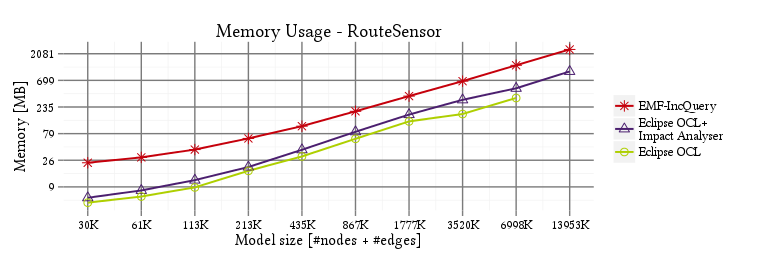
- Memory usage: heap memory usage measured at the end of the execution.
The raw results can be downloaded here, while the diagrams are presented below.
Batch validation
SwitchSensor
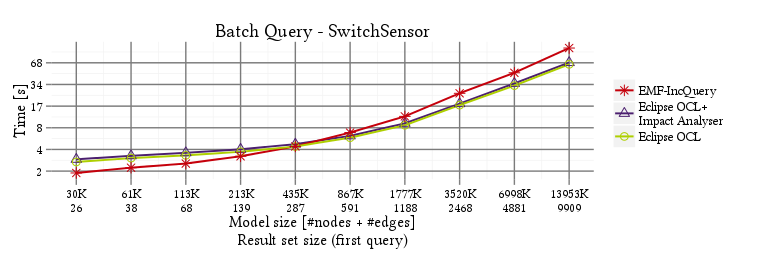
PosLength
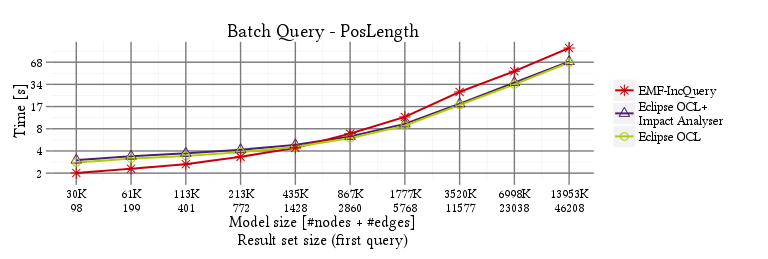
RouteSensor
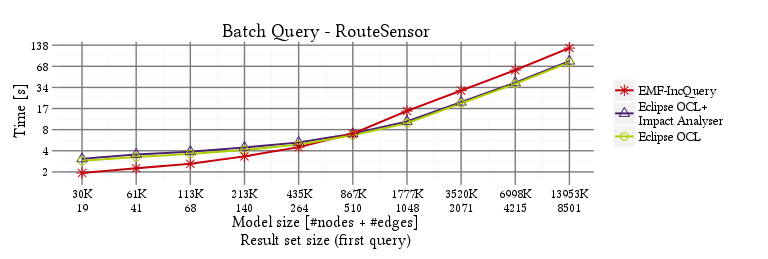
SignalNeighbor
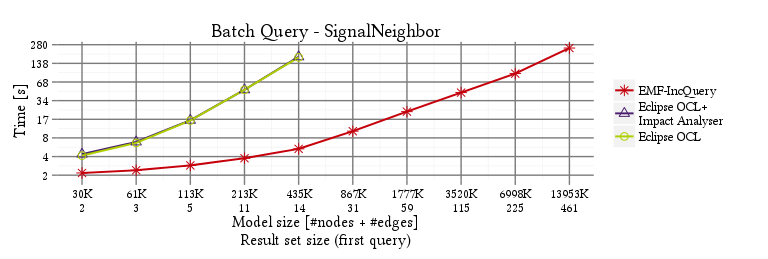
On-the-fly revalidation
SwitchSensor
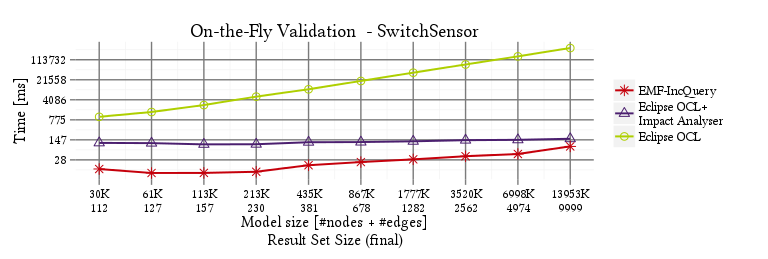
PosLength

RouteSensor
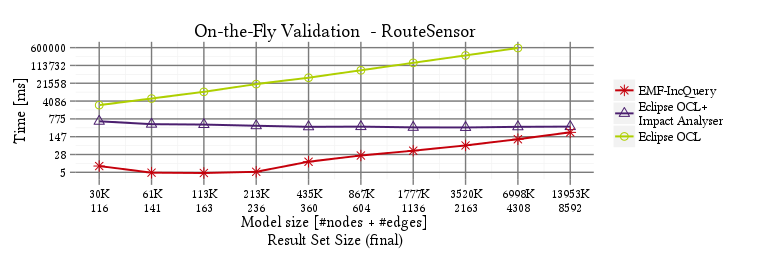
SignalNeighbor
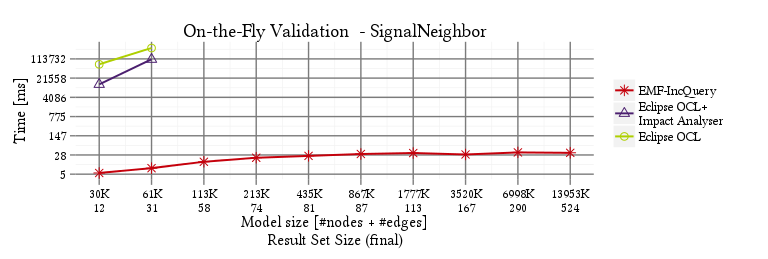
Memory overhead
SwitchSensor
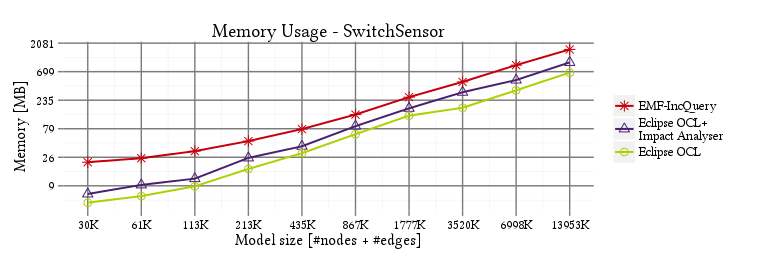
PosLength
RouteSensor
SignalNeighbor