IncQuery-D: Incremental Graph Search in the Cloud
Authors: Benedek Izsó, Gábor Szárnyas, István Ráth and Dániel Varró
This benchmark page was created to supplement the article: IncQuery-D: Incremental Graph Search in the Cloud.
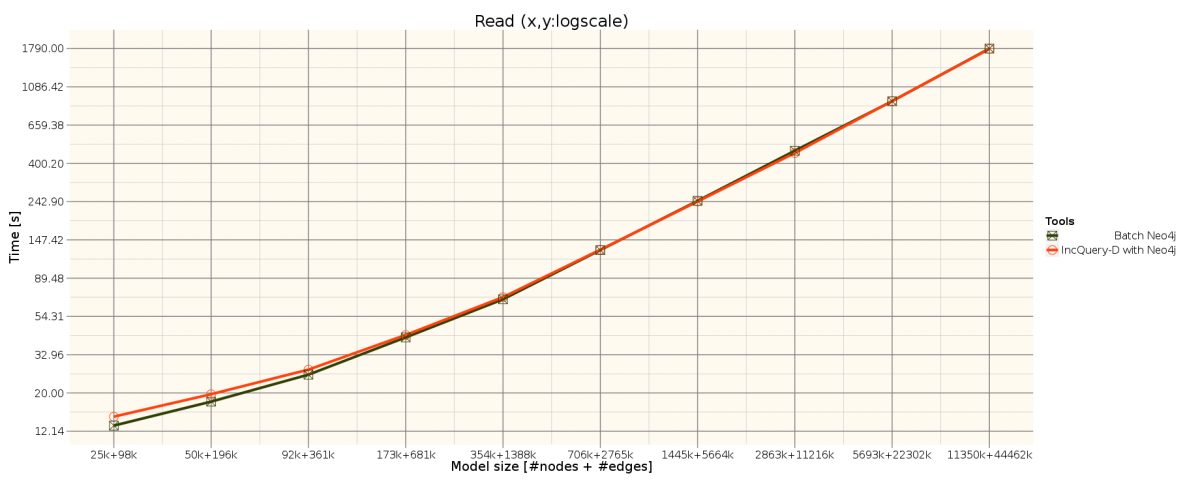
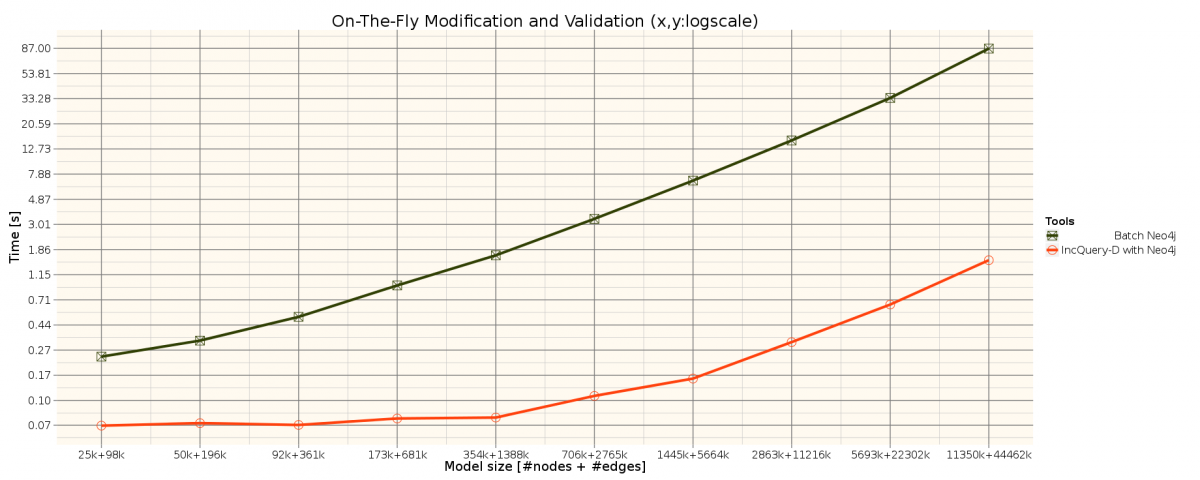
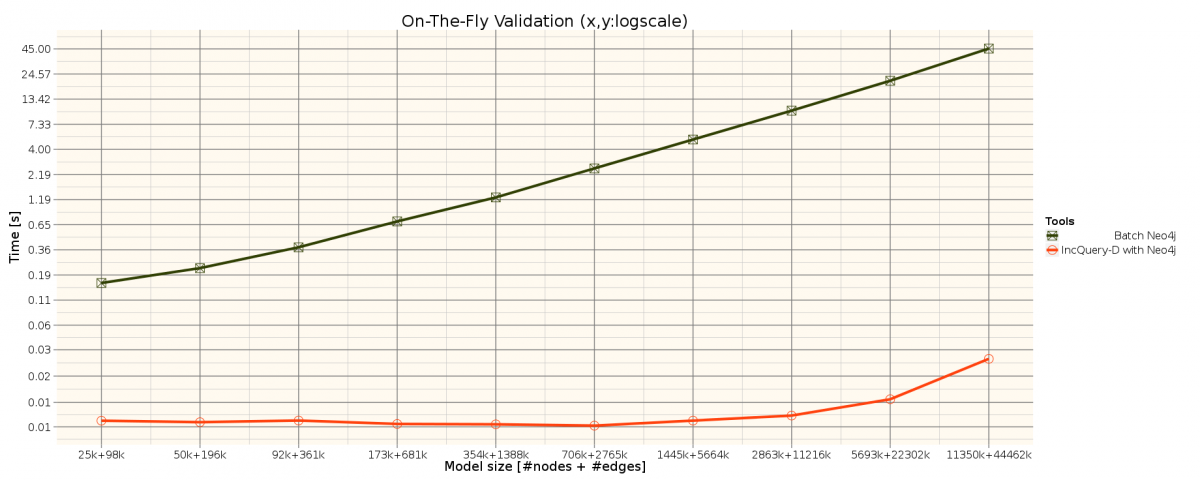
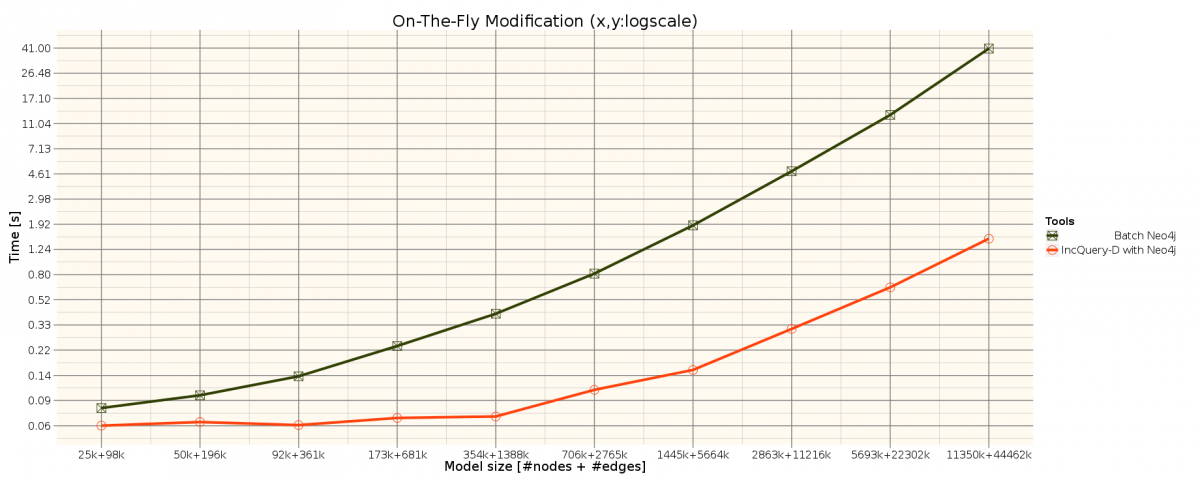
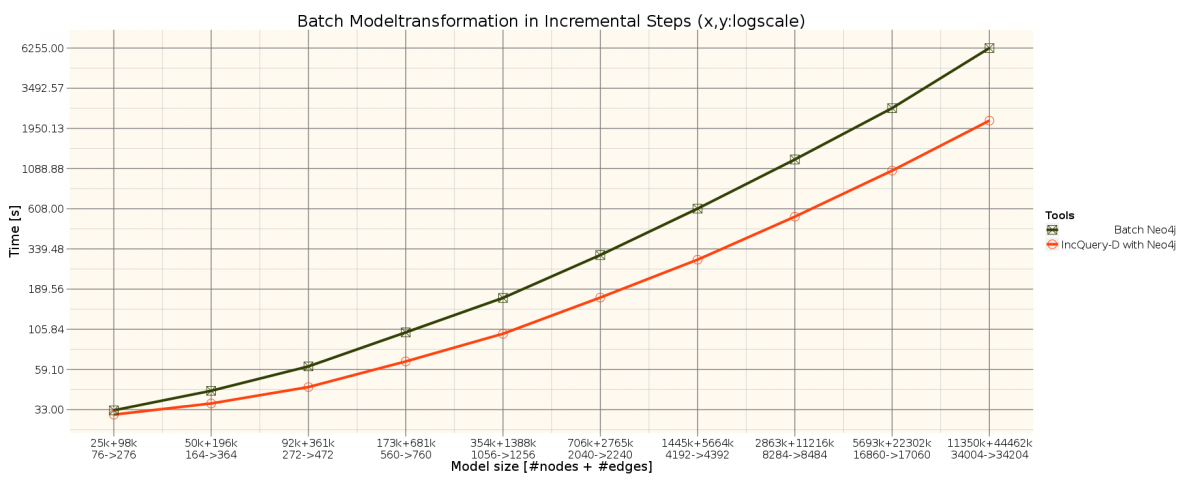
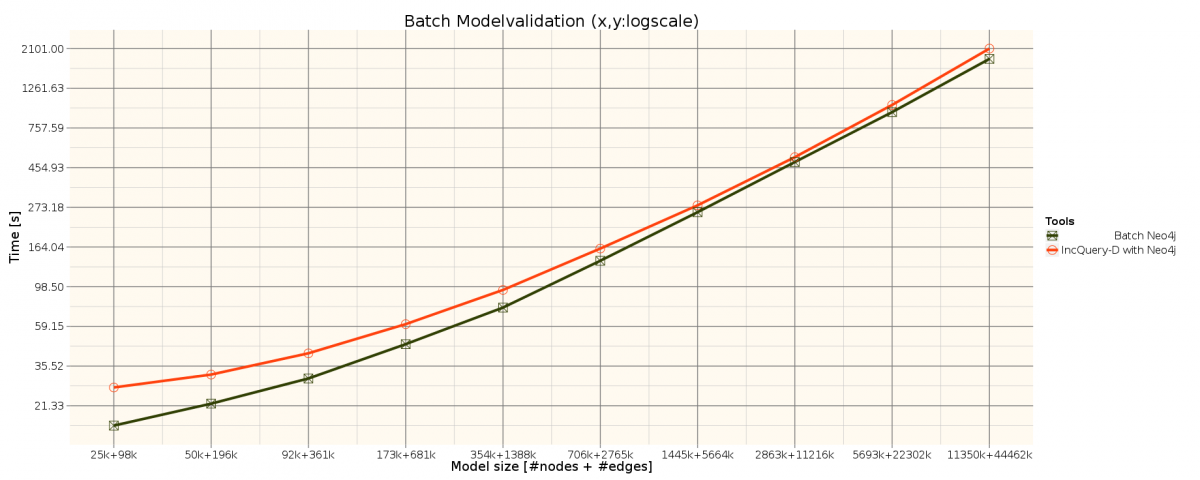
The benchmark is based on the TrainBenchmark's RouteSensor well-formedness constraint. See the metamodel and the query description.
Benchmarking environment
Technical details
The exact versions of the used software tools and parameters of the measurement hardware are shown in the following list. Execution times were recorded using the System.nanoTime() but in the diagrams only milliseconds are shown.
- Software:
- Ubuntu 12.10 64 bit
- Oracle JDK 1.7
- Neo4j 1.8
- Akka 2.1.2
- Hardware:
- CPU: 2 cores of an Intel® Xeon® Processor L5420 processor @ 2.5 GHz
- 16 GB RAM
Measurement process
Generating instance models
We used the TrainBenchmark's generator project to generate the Neo4j GraphML files in different sizes. The model generator instantiated generated the property graph models in different sizes ranging from a few thousand elements up to approx. 8×106, to scale the experiment up to large model sizes reported in the industry. The generator randomly introduced faulty element configurations into the model (with approx. hit rates of 10% for the RouteSensor requirement).
Generating graph segments
To create different shards, we derived a unique graph ("graph segment") for each virtual machine. We generate the graph segments by appending a number in front of each "idx" (our custom surrogate-key identifier). Note that the maximum idx in the size 2048 file is 11382691, so if we append a 40000000 (20000000, ...) in front and we'll get 4000000011382691 (~2 pow 52), which fits easily in a long.
cat testBig_User_512.graphml | sed s/idx\"\>/idx\"\>10000000/g > testBig_User_512_A.graphml
Script for generating all segments:
#!/bin/bash
graphs=(A B C D)
rm -rf segments
mkdir segments
for (( i = 0; i < ${#graphs[@]}; i++ )); do
echo ${graphs[$i]}
idx=$((i+1))
for f in *.graphml; do
echo $f;
cat $f | sed "s/idx\">/idx\"\>${idx}0000000/g" > segments/${f/\.graphml/_${graphs[$i]}.graphml}
done
done;
Separate scripts for each segments (e.g. if you wish to generate the models separately on each server):
for f in *.graphml; do
echo $f;
cat $f | sed "s/idx\">/idx\"\>10000000/g" > ~/bigmde/${f/\.graphml/_A.graphml}
done
for f in *.graphml; do
echo $f;
cat $f | sed "s/idx\">/idx\"\>20000000/g" > ~/bigmde/${f/\.graphml/_B.graphml}
done
for f in *.graphml; do
echo $f;
cat $f | sed "s/idx\">/idx\"\>30000000/g" > ~/bigmde/${f/\.graphml/_C.graphml}
done
for f in *.graphml; do
echo $f;
cat $f | sed "s/idx\">/idx\"\>40000000/g" > ~/bigmde/${f/\.graphml/_D.graphml}
done
Settings
- See Neo4j's Linux specific notes and set up your Linux servers accordingly:
- Edit the /etc/security/limits.conf as root and add these two lines:
your_username soft nofile 40000 your_username hard nofile 40000
- Edit the /etc/pam.d/su file as root. Uncomment or add the following line:
session required pam_limits.so
- Restart the machine.
Akka settings
Settings in the akka-2.1.2/config directory.
- common.conf
akka { actor { provider = "akka.remote.RemoteActorRefProvider" } remote { netty { hostname = "10.6.21.231" } } } - project files
- src/main/resources directory:
- application.conf
calculator { include "common" akka { remote.netty.port = 2552 } } remotecreation { include "common" akka { actor { deployment { /SwitchPosition_switchActor { remote = "akka://ReteNet@10.6.21.231:2552" } /Route_switchPositionActor { remote = "akka://ReteNet@10.6.21.233:2552" } /TrackElement_sensorActor { remote = "akka://ReteNet@10.6.21.235:2552" } /Route_routeDefinitionActor { remote = "akka://ReteNet@10.6.21.237:2552" } /JoinNode1 { remote = "akka://ReteNet@10.6.21.233:2552" } /JoinNode2 { remote = "akka://ReteNet@10.6.21.235:2552" } /AntiJoinNode { remote = "akka://ReteNet@10.6.21.237:2552" } /ProductionNode { remote = "akka://ReteNet@10.6.21.231:2552" } } } remote.netty.port = 2554 } }
- application.conf
- common.conf: the localhost IP address (opposed to the common.conf file in the microkernel's config directory)
akka { actor { provider = "akka.remote.RemoteActorRefProvider" } remote { netty { hostname = "127.0.0.1" message-frame-size = 10000000000 } } } - config.properties
GRAPHML_PREFIX = /home/szarnyasg/bigmde/testBig_User_ GRAPHML_EXTENSION = .graphml MODELSIZE = 1 VM0 = 10.6.21.231 VM1 = 10.6.21.233 VM2 = 10.6.21.235 VM3 = 10.6.21.237
- src/main/resources directory:
Deploy
Script for deploying to the cloud:
#!/bin/bash
# constants
user=szarnyasg
akkaver=2.1.2
akkadir=~/akka-$akkaver
projectname=bigmde.incqueryd
projectdir=~/git/incqueryd/$projectname
machines=(vcl0 vcl1 vcl2 vcl3)
# variables
maven=true
coordinator=${machines[0]}
cd $projectdir
mvn clean install
mv target/$projectname*.jar target/$projectname.jar
# copying to coordinator
echo $coordinator
scp target/$projectname.jar $user@$coordinator:$akkadir/deploy/
for ((i = 1; i < ${#machines[@]}; ++i))
do
machine=${machines[i]}
echo $machine
ssh $user@$coordinator "scp $akkadir/deploy/$projectname.jar $user@$machine:$akkadir/deploy"
done
cd
echo Done.
Memory settings
- Akka: in the distributed-rete/akka-conf/bin/akka file:
[ -n "$JAVA_OPTS" ] || JAVA_OPTS="-Xms3500M -Xmx3500M -Xss1M -XX:MaxPermSize=256M -XX:+UseParallelGC"
- Neo4j: in the distributed-rete/neo4j-conf/neo4j-wrapper.conf file:
# Initial Java Heap Size (in MB) wrapper.java.initmemory=3500 # Maximum Java Heap Size (in MB) wrapper.java.maxmemory=3500
Measurement results